Unsere schöne API wird immer besser, nun ist auch das Monitoring aktiviert: Vertrauen ist gut – Kontrolle ist besser.

Photo by Carlos Muza on Unsplash
Um immer auf dem Laufenden zu sein, wie es unserem System geht, haben wir verschiedenste Monitoring-Ansätze integriert.
Mit dem Infrastruktur-Monitoring sichern wir zunächst nur die elementare Grundvoraussetzung ab und stellen fest, ob die API überhaupt funktionieren kann. Überwacht werden dabei z.B. die Auslastung von CPU, Hauptspeicher, Festplatten und Netzwerk.
Mit unserem in die Anwendung integrierten Agenten registrieren wir eingehende Anfragen, die dazugehörigen Antworten, Verarbeitungsdauer und bemerken Exceptions. All diese Informationen werden an ein Monitoring Tool übermittelt und bilden unser Passives Monitoring.
Jedoch auch dieser Monitoring-Typ stößt an seine Grenzen, wenn man sich vorstellt, dass eine Zeit lang keine Requests an unsere API gestellt werden. Aus diesem Grund rufen wir über unser Synthetisches Monitoring die verschiedenen API-Endpunkte tatsächlich so auf, wie wir es von unseren Konsumenten annehmen oder erwarten.
Alle oben genannten Monitore benötigen Metriken, die dann in Tools wie Prometheus oder Datadog weiterverarbeitet werden können.
Doch was sind Metriken und welche Metriken sind sinnvoll?
Metriken erfassen einen Wert, der sich auf unsere Systeme zu einem bestimmten Zeitpunkt bezieht – zum Beispiel die Anzahl der Benutzer, die derzeit bei einer Webanwendung angemeldet sind. Daher werden Metriken normalerweise einmal pro Sekunde, einmal pro Minute oder in einem anderen regelmäßigen Intervall erfasst, um ein System im Laufe der Zeit zu überwachen.
Es gibt zwei wichtige Kategorien von Metriken: Arbeitsmetriken und Ressourcenmetriken. Für jedes System, das Teil unserer Softwareinfrastruktur ist, finden wir heraus, welche Arbeits- und Ressourcenmetriken verfügbar sind und sammeln diese.
Arbeitsmetriken
Sie zeigen den Zustand unseres Systems auf höchster Ebene an. Bei der Betrachtung der
Arbeitsmetrik ist es oft hilfreich, sie in vier Untertypen aufzuteilen:
-
Durchsatz ist die Arbeitsmenge, die das System pro Zeiteinheit verrichtet. Der Durchsatz wird normalerweise als absolute Zahl aufgezeichnet. Für einen Webserver sind das z.B. die Anzahl der Requests pro Sekunde.
-
Erfolgsmetriken stellen z.B. für einen Webserver den Prozentsatz der erfolgreich bearbeiteten Requests dar, also die Responses mit HTTP 2xx.
-
Fehlermetriken erfassen die Anzahl fehlerhafter Ergebnisse, die normalerweise als Fehlerrate pro Zeiteinheit ausgedrückt oder durch den Durchsatz normalisiert wird, um Fehler pro Arbeitseinheit zu zählen. Fehlermetriken werden oft getrennt von Erfolgsmetriken erfasst, wenn es mehrere potenzielle Fehlerquellen gibt, von denen einige schwerwiegender sind als andere. In unserem Webserver-Beispiel ist das der Prozentsatz der Responses mit HTTP 5xx.
-
Leistungsmetriken quantifizieren, wie effizient eine Komponente ihre Arbeit verrichtet. Die häufigste Leistungsmetrik ist die Latenz, die die Zeit darstellt, die zum Abschließen einer Arbeitseinheit erforderlich ist. Die Latenz kann als Durchschnitt oder in Prozent ausgedrückt werden, z. B. “99 Prozent der Anfragen werden innerhalb von 0,1 Sekunde zurückgegeben“.
Diese Metriken sind unglaublich wichtig für das Monitoring. Damit ist es möglich, die dringendsten Fragen zum inneren Zustand und der Leistung eines Systems schnell zu beantworten: Ist das System verfügbar und tut es aktiv, wofür es gebaut wurde? Wie ist die Performance? Welche Fehlerrate hat das System?
Ressourcenmetriken
Die meisten Komponenten unserer Softwareinfrastruktur dienen als Ressource für andere Systeme. Einige Ressourcen sind Low-Level-Ressourcen – zum Beispiel umfassen die Ressourcen eines Servers physische Komponenten wie CPU, Arbeitsspeicher, Festplatten und Netzwerkschnittstellen. Aber auch eine übergeordnete Komponente wie eine Datenbank kann als Ressource betrachtet werden, wenn ein anderes System diese Komponente benötigt.
Ressourcenmetriken können uns helfen, ein detailliertes Bild des Systemzustands zu rekonstruieren, was sie für die Untersuchung und Diagnose von Problemen besonders wertvoll macht. Wir sammeln für jede Ressource in unserem System Metriken, die vier Schlüsselbereiche abdecken:
-
Die Auslastung ist der Prozentsatz der Zeit, in der die Ressource ausgelastet ist, oder der Prozentsatz der Kapazität der Ressource, die verwendet wird.
-
Der Sättingszustand (z.B. einer Queue) ist ein Maß für die Menge der Tasks, die die Ressource noch nicht bedienen kann und die sich noch in der Warteschlange befinden.
-
Fehler stellen interne Fehler dar, die während des Betriebs möglicherweise nicht beobachtbar sind.
-
Verfügbarkeit stellt den Prozentsatz der Zeit dar, in der die Ressource auf Anfragen geantwortet hat. Diese Metrik ist nur für Ressourcen klar definiert, die aktiv und regelmäßig auf Verfügbarkeit überprüft werden können.
Zur Veranschaulichung eine Übersicht der Metriken für verschiedene Ressourcen:
|
Microservice |
durchschnittlicher Prozentsatz der Zeit, in der der Service ausgelastet war |
nicht verarbeitete Requests |
interne Fehler des Microservices |
Prozentsatz der Zeit, in der der Microservice erreichbar war |
|
Datenbank |
durchschnittlicher Prozentsatz der Zeit, in der jede Datenbankverbindung ausgelastet war |
nicht verarbeitete Anfragen |
interne Fehler, z.B. Replication-Fehler |
Prozentsatz der Zeit, in der die Datenbank erreichbar war |
Metrik-Typen
Neben den Kategorien für Metriken sind noch die verschiedenen Typen von Metriken wichtig. Der Metrik-Typ hat Einfluß darauf, wie die entsprechenden Metriken in einem Tool wie Datadog oder Prometheus angezeigt werden.
Folgende verschiedene Typen gibt es:
-
Count
-
Rate
-
Gauge
-
Histogramm
Der Metrik-Typ Count repräsentiert die Anzahl von Ereignissen während eines bestimmten Zeitintervalls. Er wird beispielsweise genutzt, um die Gesamtanzahl aller Verbindungen zu einer Datenbank oder die Anzahl der Requests zu einem Endpunkt zu erfassen. Der Metrik-Typ Count unterscheidet sich vom Metrik-Typ Rate, welcher die Anzahl der Ereignisse pro Sekunde in einem definierten Zeitintervall erfasst. Mit dem Metrik-Type Rate kann erfasst werden, wie oft Dinge passieren, wie z.B. die Häufigkeit des Verbindungsaufbaus zu einer Datenbank oder Requests zu einem Endpunkt. Der Metrik-Typ Gauge gibt für ein bestimmtes Zeitintervall einen Snapshot-Wert zurück. Es wird jeweils der letzte Wert innerhalb eines Zeitintervalls zurückgegeben. Eine Metrik mit dem Gauge-Typ wird vor allem dafür genutzt, Werte kontinuierlich zu messen, z.B. den verfügbaren Festplattenplatz. Mit dem Metrik-Typ Histogramm lässt sich die statistische Verteilung von bestimmten Werten während eines definierten Zeitintervalls bestimmen. Dafür gibt es die Möglichkeit “Durchschnitt”, “Anzahl”, “Mittelwert” oder “Maximum” von den gemessenen Werten zu bestimmen.
Events
Zusätzlich zu Metriken, die mehr oder weniger kontinuierlich erfasst werden, können einige Monitoringsysteme auch Events erfassen: diskrete, seltene Ereignisse, die einen entscheidenden Anteil für das Verständnis der Verhaltensänderungen unseres Systems liefern können. Einige Beispiele:
-
Änderungen: interne Code-Releases, Builds und Build-Fehler
-
Warnungen: intern generierte Warnungen oder Benachrichtigungen von Drittanbietern
-
Skalieren von Ressourcen: hinzufügen oder entfernen von Hosts
Im Gegensatz zu einem einzelnen metrischen Datenpunkt, der im Allgemeinen nur im Kontext aussagekräftig ist, enthält ein Event normalerweise genügend Informationen, um es selbst interpretieren zu können. Events erfassen, was zu einem bestimmten Zeitpunkt passiert ist, mit optionalen zusätzlichen Informationen.
Events werden manchmal verwendet, um Warnungen zu generieren – jemand sollte über Ereignisse benachrichtigt werden, die darauf hinweisen, dass kritische Arbeiten fehlgeschlagen sind. Aber häufiger werden sie verwendet, um Probleme zu untersuchen und systemübergreifend zu korrelieren. Events sollte man behandeln wie Metriken – sie sind wertvolle Daten, die gesammelt werden müssen, wo immer es möglich ist.
Aber wie sollten gute Daten aussehen?
Die gesammelten Daten sollten vier Merkmale aufweisen:
-
Gute Verständlichkeit
Wir sollten in der Lage sein schnell festzustellen, wie jede Metrik oder jedes Ereignis erfasst wurde und was sie darstellen. Während eines Ausfalls möchten wir keine Zeit damit verbringen herauszufinden, was unsere Daten bedeuten. Wir halten Metriken und Ereignisse so einfach wie möglich und benennen sie klar. -
Geeignetes Zeitintervall
Unsere Metriken müssen wir in geeigneten Abständen sammeln, so dass eventuelle Probleme sichtbar werden. Wenn wir zu selten Metriken oder Durchschnittswerte über lange Zeitfenster sammeln, verlieren wir möglicherweise die Fähigkeit, das Verhalten eines Systems genau zu rekonstruieren. Beispielsweise werden Perioden mit einer Ressourcenauslastung von 100 Prozent verdeckt, wenn sie mit Perioden geringerer Auslastung gemittelt werden.
Auf der anderen Seite muss man auch bedenken, dass das Sammeln von Metriken, bzw. insbesondere Synthetisches Monitoring, eine gewisse (kontinuierliche) Last bedeutet und
a) der “eigentlichen” Arbeit Ressourcen “wegnimmt” und
b) deren Daten überlagert, da sich natürlich Synthetisches Monitoring im Passiven Monitoring niederschlägt.
Wählt man also ein zu kurzes Zeitintervall, kann das dazu führen, dass das System merklich überfordert ist oder keine aussagekräftige Daten enthält. -
Bezug auf Geltungsbereich
Angenommen jeder unserer Services arbeitet in mehreren Regionen und wir können den Gesamtzustand jeder Region oder ihrer Kombinationen überprüfen. Dann ist es wichtig, die Metriken den entsprechenden Regionen zuordnen zu können, damit wir bei Problemen in der entsprechenden Region warnen und Ausfälle schnell untersuchen können. -
Ausreichend lange Datenspeicherung
Wenn wir Daten zu früh verwerfen oder unser Monitoringsystem nach einiger Zeit unsere Metriken aggregiert, um die Speicherkosten zu senken, verlieren wir wichtige Informationen über die Vergangenheit. Die Aufbewahrung unserer Rohdaten für ein Jahr oder länger macht es viel einfacher zu wissen, was „normal“ ist, insbesondere wenn unsere Metriken monatliche, saisonale oder jährliche Schwankungen aufweisen.
Mit unseren gesammelten Metriken sind wir nun in der Lage, jederzeit Auskunft über den Zustand unseres Systems geben zu können.
ABER: Wer will schon den ganzen Tag auf die erzeugten Diagramme schauen und den Zustand des Systems prüfen? Es müsste etwas geben, was uns Bescheid gibt, wenn außergewöhnliche Dinge passieren.
→ Ein Alarming-System
Auf das Wesentliche aufmerksam machen
Automatisierte Warnungen sind für das Monitoring unerlässlich. Sie ermöglichen es uns, Probleme überall in unserer Infrastruktur zu erkennen, so dass wir deren Ursachen schnell identifizieren und Service-Beeinträchtigungen und -unterbrechungen minimieren können.
Während Metriken und andere Messungen das Monitoring erleichtern, lenken Warnungen die Aufmerksamkeit auf die bestimmten Systeme, die eine Beobachtung, Inspektion und Intervention erfordern.
Aber Warnungen sind nicht immer so effektiv, wie sie sein könnten. Insbesondere echte Probleme gehen oft in einem Meer von Nachrichten verloren. Wir wollen hier einen einfachen Ansatz für eine effektive Alarmierung beschreiben:
- Alarmiere großzügig, aber mit Bedacht
- Alarmiere über Symptome statt Ursachen
Wann sollte man jemanden (oder niemanden) alarmieren?
Eine Warnung sollte etwas Bestimmtes über unsere Systeme im Klartext mitteilen: „Zwei Cassandra-Knoten sind ausgefallen“ oder „90 Prozent aller Webanfragen benötigen mehr als 0,5 Sekunden für die Verarbeitung und Antwort”. Durch die Automatisierung von Warnmeldungen für so viele unserer Systeme wie möglich können wir schnell auf Probleme reagieren und einen besseren Service bieten. Außerdem sparen wir Zeit, da wir von der ständigen, manuellen Überprüfung der Metriken befreit sind.
Stufen der Alarmierungsdringlichkeit
Nicht alle Warnungen haben die gleiche Dringlichkeit. Einige erfordern ein sofortiges Eingreifen, einige erfordern ein eventuelles Eingreifen und einige weisen auf Bereiche hin, in denen in Zukunft möglicherweise Aufmerksamkeit erforderlich ist. Alle Warnungen sollten mindestens an einem zentralen Ort protokolliert werden, um eine einfache Korrelation mit anderen Metriken und Ereignissen zu ermöglichen.
Warnungen als Datensätze (niedriger Schweregrad)
Viele Warnungen werden nicht mit einem Serviceproblem in Verbindung gebracht, sodass ein Mensch sie möglicherweise nicht einmal bemerken muss. Wenn beispielsweise ein Service auf Benutzeranfragen viel langsamer als üblich antwortet, aber nicht so langsam, dass der Endbenutzer es als störend empfindet, sollte dies eine Warnung mit geringer Dringlichkeit erzeugen. Diese wird im Monitoring aufgezeichnet und als zukünftige Referenz oder für Untersuchungen gespeichert. Schließlich verschwinden vorübergehende Probleme, die dafür verantwortlich sein könnten, wie beispielsweise Netzwerküberlastungen, oft von selbst. Sollte der Dienst jedoch eine große Anzahl von Zeitüberschreitungen zurückgeben, liefern diese Informationen eine unschätzbare Basis für unsere Untersuchung.
Warnungen als Benachrichtigungen (mittlerer Schweregrad)
Die nächste Stufe der Alarmierungsdringlichkeit betrifft Probleme, die ein Eingreifen erfordern, jedoch nicht sofort. Möglicherweise geht der Speicherplatz des Datenspeichers zur Neige und sollte in den nächsten Tagen hochskaliert werden. Das Senden einer E-Mail und/oder das Posten einer Benachrichtigung in einem speziellen Chat-Kanal ist eine perfekte Möglichkeit, diese Benachrichtigungen zu übermitteln – beide Nachrichtentypen sind gut sichtbar, aber sie wecken niemanden mitten in der Nacht und stören unseren Arbeitsfluss nicht.
Warnungen als Alarm (hoher Schweregrad)
Die dringendsten Warnungen sollten besonders behandelt und unmittelbar eskaliert werden, um schnell unsere Aufmerksamkeit zu bekommen. Reaktionszeiten für unsere Webanwendung sollten beispielsweise ein internes SLA haben, das mindestens so aggressiv ist wie unser strengstes kundenorientiertes SLA. Jeder Fall von Reaktionszeiten, die unser internes SLA überschreiten, erfordert sofortige Aufmerksamkeit, unabhängig von der Tageszeit.
Wann sollte man einen schlafenden Ingenieur liegen lassen? 😉

Photo by No Revisions on Unsplash
Wenn wir erwägen einen Alarm zu setzen, stellen wir uns drei Fragen, um die Dringlichkeit des Alarms zu bestimmen und wie er behandelt werden sollte:
-
Ist dieses Problem echt?
Es mag offensichtlich erscheinen, aber wenn das Problem nicht real ist, sollte es normalerweise keinen Alarm generieren. Die folgenden Beispiele können Alarme auslösen, sind aber wahrscheinlich nicht symptomatisch für echte Probleme. Ein Alarm bei Ereignissen wie diesen trägt zur Ermüdung des Alarms bei und kann dazu führen, dass schwerwiegendere Probleme ignoriert werden:-
Metriken in einer Testumgebung sind außerhalb der festgelegten Grenzen.
-
Ein einzelner Server verrichtet seine Arbeit sehr langsam, ist aber Teil eines Clusters mit Fast-Failover zu anderen Maschinen und wird trotzdem regelmäßig neu gestartet.
-
Geplante Upgrades führen dazu, dass eine große Anzahl von Maschinen als offline gemeldet wird.
Wenn das Problem tatsächlich vorliegt, sollte eine Warnung generiert werden. Auch wenn die Warnung nicht mit einer Benachrichtigung (per E-Mail oder Chat) verknüpft ist, sollte sie in unserem Monitoringsystem zur späteren Analyse und Korrelation aufgezeichnet werden.
-
-
Erfordert dieses Problem Aufmerksamkeit?
Es gibt sehr reale Gründe, jemanden von der Arbeit, dem Schlaf oder der privaten Zeit abzurufen. Davon sollten wir jedoch nur Gebrauch machen, wenn es wirklich nicht anders geht. Das heißt, wenn wir eine Reaktion auf ein Problem angemessen automatisieren können, sollten wir dies in Betracht ziehen. Wenn das Problem aber echt ist und (menschliche) Aufmerksamkeit erfordert, sollte eine Warnung generiert werden, die jemanden benachrichtigt, der das Problem untersuchen und beheben kann. Je nach Schwere des Problems, kann das vielleicht noch bis zum nächsten Morgen warten. Wir können also verschiedene Wege zur Benachrichtigung unterscheiden: Die Benachrichtigung sollte mindestens per E-Mail, Chat oder Ticketing-System erfolgen, damit der Empfänger seine Reaktion priorisieren kann. Ansonsten sind aber auch Anrufe, Push-Benachrichtigungen aufs Handy etc. denkbar, um möglichst schnell auf ein Problem aufmerksam zu machen. -
Ist dieses Problem dringend?
Nicht alle Probleme sind Notfälle. Vielleicht war beispielsweise ein mäßig hoher Prozentsatz der Systemantworten sehr langsam oder ein leicht erhöhter Anteil der Abfragen gibt veraltete Daten zurück. Beide Probleme müssen möglicherweise bald behoben werden, jedoch nicht um 4.00 Uhr morgens.
Wenn dagegen die Performance eines Schlüsselsystems einbricht oder seine Arbeit einstellt, sollten wir sofort nachsehen. Wenn das Symptom echt ist und Aufmerksamkeit erfordert und es akut ist, sollte ein dringender Alarm generiert werden.
Zum Glück bieten Monitoring-Lösungen wie Prometheus oder Datadag die Möglichkeit, verschiedene Kommunikationswege wie E-Mail, Slack (Chat) oder auch SMS anzubinden.
Alarm zu Symptomen
Im Allgemeinen ist ein Alarm die am besten geeignete Art von Warnung, wenn das System, für das wir verantwortlich sind, keine Requests mit akzeptablem Durchsatz, Latenz oder Fehlerraten mehr verarbeiten kann. Das ist die Art von Problemen, über die wir sofort Bescheid wissen möchten. Die Tatsache, dass unser System keine nützliche Arbeit mehr leistet, ist ein Symptom – das heißt, es ist die Manifestation eines Problems, das eine Reihe verschiedener Ursachen haben kann.
Beispiel: Wenn unsere Website in den letzten drei Minuten sehr langsam reagiert hat, ist dies ein Symptom. Mögliche Ursachen sind eine hohe Datenbanklatenz, ausgefallene Anwendungsserver, hohe Last usw. Wenn möglich, bauen wir unser Alarming auf Symptomen und nicht auf Ursachen auf.
Das Alarming auf Symptomen führt zu echten, oft benutzerbezogenen Problemen und nicht zu hypothetischen oder internen Problemen. Vergleichen wir das Alarming bei einem Symptom, wie z. B. langsame Website-Reaktionen, mit dem Alarming bei möglichen Ursachen des Symptoms, z. B. einer hohen Auslastung unserer Webserver:
Unsere Benutzer werden die Serverlast nicht kennen oder sich um die Serverauslastung kümmern, wenn die Website immer noch schnell reagiert, und uns wird es ärgern, wenn wir uns um etwas kümmern müssen, das nur intern wahrnehmbar ist und ohne Eingreifen auf ein normales Niveau zurückkehren kann.
Langlebige Definition von Warnungen
Ein weiterer guter Grund auf Symptome zu verweisen, ist, dass von Symptomen ausgelöste Warnungen in der Regel dauerhaft sind. Dies bedeutet, dass wir unabhängig davon, wie sich die zugrunde liegenden Systemarchitekturen ändern können, auch ohne Aktualisierung unserer Alert-Definitionen eine entsprechende Nachricht erhalten, wenn das System nicht mehr so funktioniert, wie es sollte.
Ausnahme von der Regel: Frühwarnzeichen
Es ist manchmal notwendig, unsere Aufmerksamkeit auf eine kleine Handvoll Metriken zu lenken, selbst wenn das System angemessen funktioniert. Frühwarnwerte spiegeln eine inakzeptabel hohe Wahrscheinlichkeit wider, dass sich bald ernsthafte Symptome entwickeln und ein sofortiges Eingreifen erforderlich ist.
Festplattenspeicher ist ein klassisches Beispiel. Im Gegensatz zu einem Mangel an freiem Speicher oder CPU wird das System wahrscheinlich nicht wiederhergestellt, wenn uns der Festplattenspeicher ausgeht, und wir haben gewiss nur wenig Zeit, bis unser System hart stoppt. Wenn wir jemanden mit ausreichend Vorlaufzeit benachrichtigen können, müssen wir natürlich niemanden mitten in der Nacht wecken. Besser noch, wir können einige Situationen antizipieren, in denen der Speicherplatz knapp wird, und eine automatische Korrektur basierend auf den Daten erstellen, die wir uns leisten können, z. B. Protokolle oder Daten zu löschen, die an anderer Stelle vorhanden sind.
Fazit: Symptome ernst nehmen
-
Wir senden nur einen Alarm, wenn Symptome schwerwiegender Probleme in unserem System erkannt werden oder wenn eine kritische und endliche Ressourcengrenze (z.B. Festplattenplatz) bald erreicht wird.
-
Wir richten unser Monitoringsystem so ein, dass es Warnungen aufzeichnet, sobald erkannt wird, dass
echte Probleme in unserer Infrastruktur aufgetreten sind, auch wenn diese Probleme noch nicht die Gesamtleistung beeinträchtigt haben.
Prozessketten-Monitoring
Hurra, wir bekommen einen Alarm: “Unser Storage-System ist ausgefallen”.
Noch ist das kein Grund zum Jubeln, da der Chef vor der Tür steht und wissen will, welche Business-Funktionen davon betroffen sind. Mit unserem derzeitigen Setup ist es nicht möglich, diese Informationen sofort bereitzustellen.
Lasst uns das an einem Beispiel näher betrachten: Eine hypothetische Firma betreibt interne und externe Services. Die externen konsumieren interne Services. Beide Arten von Services haben Abhängigkeiten zu Ressourcen, wie z.B. unser Storage-System. Mit einem Dependency Tree ist es möglich, diese Abhängigkeiten zu modellieren. Fällt nun ein Element in unserem Baum aus, kann automatisiert ermittelt werden, welche abhängigen Systeme betroffen sind. Dies ermöglicht Vorabinformationen an Helpdesk, First-Level-Support etc. und nimmt damit Druck und Stress vom bearbeitenden Team.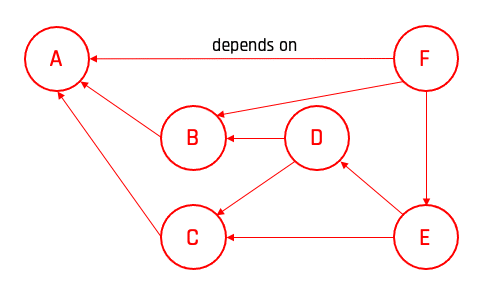
Durch Verwendung gewichteter Knoten erhält man die Möglichkeit, die Kritikalität zu berechnen. Was wiederum ermöglicht, die Arbeit an einzelnen Ausfällen zu priorisieren.
Aber parallele Ausfälle treten ja zum Glück nur in der Theorie auf und schon gar nicht an Wochenenden oder Feiertagen. 😉
Anzumerken ist hier, dass die IT-Landschaft in Unternehmen “lebt”. Die Konsequenz daraus ist, dass, wer sich ein derartiges End-to-End-Monitoring leistet, dieses Modell/Tool auch aktuell halten muss. Dies bedeutet immer Aufwand, der sich oft nur für kritische Unternehmensprozesse lohnt. Wenn zum Beispiel ein Bot ausfällt, der in einem Chat Tool den aktuellen Speiseplan der Kantine veröffentlicht, so lohnt es sich nicht, hierfür ein End-to-End-Monitoring auszurollen.
Fazit
Monitoring versetzt uns in die Lage, jederzeit Aussagen über den Zustand unserer Systeme zu tätigen. Alarming lenkt die Aufmerksamkeit auf Systemanomalien. Prozessketten-Monitoring erlaubt uns eine Aussage hinsichtlich der Auswirkungen von Anomalien.
Voraussetzung für ein sinnvolles und gelungenes Monitoring- und Alarming-System ist ein Gesamtkonzept, welches zuvor erarbeitet und ständig überarbeitet werden muss.