
What's the problem?

In recent years, I have seen a number of software projects commonly referred to as CRUD applications. These applications are very data-centric and offer many tabular views in the UI.
The projects usually had a classic 3-layer architecture but beyond that, they were not very modularized. What was initially a sufficient approach has over time grown into an unstructured monolith; otherwise known as the "Big Ball of Mud".
The following illustration shows the dependencies of such an application.
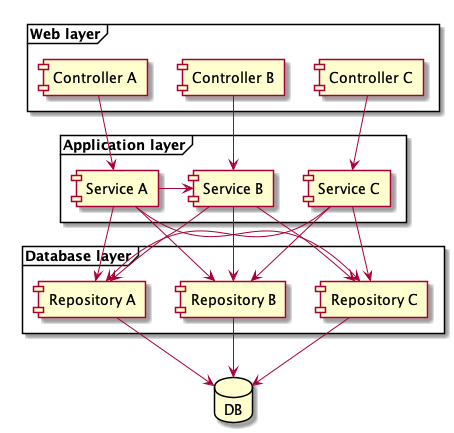
As can be seen, the services share several repositories. This leads to a tight coupling and makes it increasingly difficult to adapt the system. The pain felt by developers increases with every change.
It therefore seems to be a challenge to cleanly modularize the large number of different queries for the tabular view – which causes the repositories to grow and grow.
The tabularization often requires aggregations across multiple entity types. There are usually no clear rules as to where one specific code belongs to.
In the end, Application Service A uses both Repository A and Repository B to implement its aggregation. Application Service B, for its part, also uses Repository A and B for its aggregations ...
The command query separation pattern offers an alternative to these growing repositories.
What’s the Command Query Separation Pattern?
In his book "Object-Oriented Software Construction", Bertrand Meyer already introduced the idea of separating read and write operations in 1988.
Since then, the pattern has been known as Command Query Separation (CQS) and is therefore a well-known concept in software development. However, it seems that it is often overlooked and its positive impact on code is underestimated.
The following Java listings show one way of implementing the pattern. Only the query part of the pattern is shown. The command part can be implemented in the same way.
1interface Query {
2}
3
4interface Response {
5}
6
7interface QueryHandler<Q extends Query, R extends Response> {
8 boolean canExecute(Query query);
9 R execute(Q query);
10}
The query class represents the type of query and the values to be filtered for. The query handler implements the actual query and the response class contains the result.
In the following abbreviated example, the name of a user is determined based on their email address.
1@RequiredArgsConstructor
2@Getter
3class UserNameByEmailQuery implements Query {
4 private final Email email;
5}
6
7@RequiredArgsConstructor
8@Getter
9class UserNameResponse implements Response {
10 private final String userName;
11 private final String fullName;
12}
13
14@RequiredArgsConstructor
15class UserNameByEmailQueryHandler
16 implements QueryHandler<UserNameByEmailQuery, UserNameResponse> {
17
18 private final NamedParameterJdbcTemplate namedParameterJdbcTemplate;
19
20 @Override
21 public boolean canExecute(Query query) {
22 return query instanceof UserNameByEmailQuery;
23 }
24
25 @Override
26 public UserNameResponse execute(UserNameByEmailQuery query) {
27 var sqlEmailParameter = new MapSqlParameterSource()
28 .addValue("queryEmail", query.getEmail().toString());
29
30 return namedParameterJdbcTemplate.queryForObject(
31 "SELECT user_name, full_name FROM users WHERE email = :queryEmail"
32 , sqlEmailParameter
33 , (resultSet, rowNum) -> new UserNameResponse(
34 resultSet.getString("user_name"),
35 resultSet.getString("full_name")));
36 }
37
38}
The following listing shows a query executor service that recognizes all query handlers and calls the corresponding handler depending on the query type.
1class QueryExecutorService {
2
3 List<QueryHandler> queryHandlers = getAllQueryHandler();
4
5 Response executeQuery(Query query) {
6 return queryHandlers.stream()
7 .filter(queryHandler -> queryHandler.canExecute(query))
8 .map(queryHandler -> queryHandler.execute(query))
9 .findAny()
10 .orElseThrow(() -> new RuntimeException("No QueryHandler found."));
11 }
12
13}
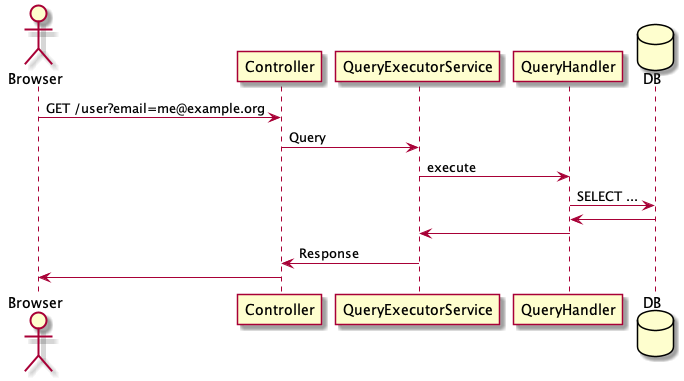
The sequence diagram shows how a query request is executed.
How can the Command Query Separation Pattern help?
The consistent separation into status-changing commands and read-only queries offers many advantages.
The read queries can usually be executed without having to observe business rules, as there is no change in status. Adjustments to the queries can therefore be considered separately from the adjustments to the business rules. This positively affects the modularization and reduces the cognitive load on developers.
It also clearly defines where code belongs, even if it aggregates several entity types.
The pattern also makes it easier to give all query handlers a read-only database connection that can be served by a read replica. This helps to scale the application if necessary.
How to implement the Command Query Separation Pattern step by step
In relation to the described CRUD applications, one can start to extract the many different queries as query handlers. What often remains are repositories with the methods findById, save and delete. These "simple" repositories can be uniquely assigned to the application services. This reduces the originally problematic coupling, as an application service A now only requires one repository A.
The following figure shows the structure after extracting the queries.
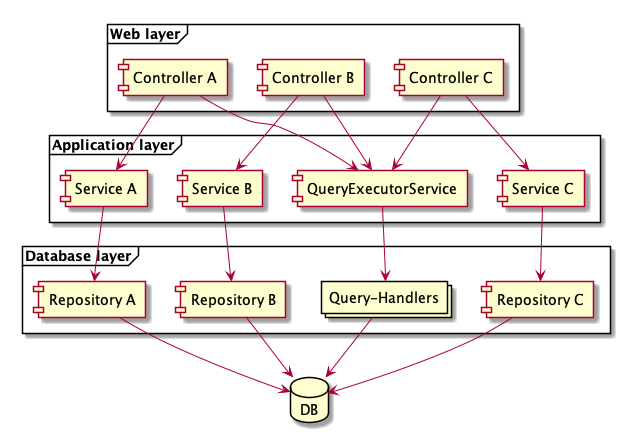
Through further refactoring, the remaining code of the application services could still be extracted as a command handler. Whether or not the effort is worth it must be decided by each project. In the CRUD applications described, the gained modularization after extracting the query handlers was often good enough to ease the developers' pain.
Finally, I would like to point out that the coupling could also have been reduced with clear rules for structuring the repositories, even without CQS. However, my experience shows that this rarely happens in practice.
With CQS, this structuring is inherent in the pattern, and it is much easier to avoid further growth of repositories.
Conclusion
The CQS pattern can provide good assistance and improve modularization through a predefined structure and clear separation of responsibilities.
The pattern can also be combined with other approaches, such as domain-driven design. It can also be extended to the command-query-responsibility-segregation pattern.




