
Photo by Nour Wageh on Unsplash
We are all familiar with pyramids. The best known are probably the pyramids that Egyptian pharaohs built as burial sites and a reflection of the hierarchy of the social structure. However, pyramids were built independently and completely autonomously by tribes living far apart from each other. Today, we know pyramids from all over the world: Egypt, Latin America, China, Greece, Rome, … What they have in common is that they are mainly buildings with a religious and/or ceremonial character, for example as part of a funerary cult.
But what exactly does this have to do with software and the testing of software? Is it also a construct with a ceremonial or religious character? The answer to this question probably depends very much on who you ask … Is it even a death cult? Hopefully not – our software should live!
And a completely different pyramid makes an important contribution to this: the test pyramid.
In the mythological interpretation of step pyramids, it was a huge stone staircase to heaven, the “house of eternity” for a king, which allowed him to attain immortality. Immortality sounds good, perhaps that’s what we want for our software too. However, perhaps we shouldn’t approach the subject like Cheops, the evil pharaoh who forced all his subordinates to help build the pyramids.
Our motivation to help build the (test) pyramid can perhaps be found in the benefits that people in Latin America derived from their pyramids: those pyramids were the substructures of busy plateaus on which houses, palaces and temples were built. These structures were thus protected from flooding during often heavy rainfall. This protection is potentially vital.
The same can be said for tests in software development – our test pyramids. Admittedly, despite their importance, in places they are more like burial mounds, the logical architectural and structural development of which were the Egyptian pyramids. So if the tests in your project still look more like a hill than a pyramid, don’t worry – you’re not the first (and probably not the last) to feel this way. And there is hope. The many pyramids in Latin America were sometimes even built over several times.
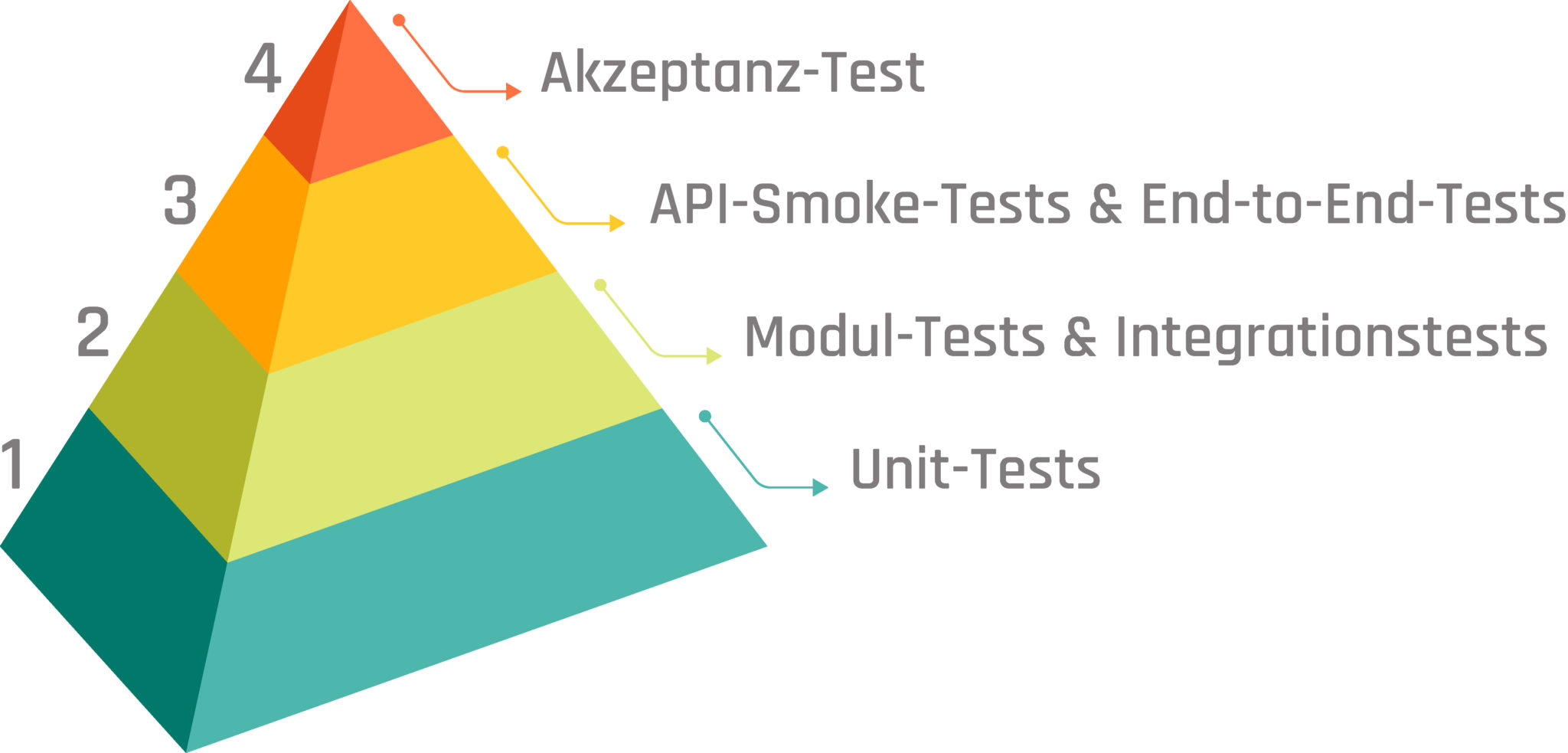
Pyramid Level 1: Unit Tests

Photo by Xavi Cabrera on Unsplash
So let’s start our consideration of the software test pyramid with small hills, of which we can build many without much effort in order to give the rest of the structure a broad base. Let’s start with the unit tests. As the smallest elements of our test pyramid, they may even be its building blocks. Unit tests check a single, individual piece of code. This could be a component or function, for example. The basic rule for this piece of code is that it is the smallest testable unit for which there are only a few input values and usually a single result.
Everything that is not in the scope of this single “unit” is mocked, stubbed or replaced by fake objects. The aim is to isolate the code to be tested so that clear and unambiguous input and output values are guaranteed. Ideally, such tests are written before the code to be tested even exists. Robert C. Martin (“Uncle Bob”) has established three laws for such test-driven development:
-
- You must not write production code until you have written a failing unit test for it.
- The unit test must not contain more code than is necessary for the test to compile correctly and fail.
- Only write as much productive code as is necessary for the previously failing test to run successfully.
That works quickly. And you quickly have a lot of tests that are created in parallel with the development and can tell us at any time whether a change has broken something. It is therefore important to concentrate on a single aspect, a single concept or even just use one assertion in the unit tests. If a unit test fails, it should be immediately clear what exactly did not work and broke. Errors discovered quickly and easily in this way are much more difficult to uncover in later test phases.
These tests are therefore an essential part of the build process and should always be carried out frequently and regularly in order to obtain feedback quickly and regularly.
Logically, we as developers write the unit tests ourselves, for ourselves and other developers. If we had to wait for someone (a tester) to write unit tests for us first, the advantage of speed would be lost. This would be quite absurd, especially in view of the fact that significantly more test code may be created for one line of productive code. At the same time, this makes it clear that it is advisable to concentrate on testing components, which also has an impact on the behaviour of the software as a whole. For example, it may not make much sense to test every getter and setter of an object. The added value of testing is much greater if we concentrate on covering all paths when making loops and decisions. We should use realistic data as input values to avoid surprises later on.
If we take all this into account, we also have another advantage that should not be neglected: our tests document the behaviour we expect. We – and anyone who might join the project later and be confronted with our code and the associated tests – can thus better understand what works how (and why).
However, all of this only relates to the components tested individually in the unit tests. We will not find every bug and every error. And we probably won’t be able to identify any problems that only arise during integration, i.e. when interacting with other components. That’s what the next level of our test pyramid is for.
Pyramid Level 2: Module Tests & Integration Tests

Photo by Bonneval Sebastien on Unsplash
We move a little further up our pyramid. We consider the smallest testable units to be sufficiently tested and now turn our attention to their interaction. Up to this point, we have dealt with the unit tests, which ideally were created in parallel to the implementation, in particular with internal structures and functionalities. This means that we were travelling in the area of white box tests with the unit tests.
If we turn our attention to the modules (sometimes also referred to as components), knowledge of such internal aspects can be helpful, but is also a question of judgement and test strategy when it comes to the actual design of the tests. We are gradually moving into the area of black box testing. We have already dealt with these two approaches to software testing in more detail some time ago:
With module tests, we can consider several small units as belonging together and test them together as a group. For example, this could be a more complex functionality in a service of an application. Other parts of the application are replaced by mocks or stubs that specify clearly defined behaviour for all aspects of the application, that are not currently relevant, without being directly dependent on their actual implementation (and immediately affected by changes). For Spring Boot applications, for example, it is possible to test individual layers of the application separately. This means that only part of the application is actually initialised and executed for the execution of the tests, which has a positive effect on the runtime of the tests. This is important because we still want to receive feedback quickly and often and execute the module tests automatically as part of the build process.
On the other hand, it is also conceivable to view the entire application as a module (of a larger system) and thus test it as a whole, as a black box. In this case, we would only use mocks and stubs for external dependencies that are not directly part of our application. This could be, for example, interaction with an authentication server or identity provider. For test execution, the application can be started locally and called “from outside” with libraries such as REST-assured. This means that the tests also run through all the security mechanisms that are intended for the application, while other module test options only start later and therefore skip or bypass the first levels of request handling.
Whether you are focusing on more complex functionality within an application or an application as a whole, the focus is on detecting errors that arise during the integration and interaction of various small units of our software. We want to make sure that everything is properly connected and works together.
Of course, we cannot cover every conceivable and inconceivable scenario. Instead, we assume that the majority of potential error cases have already been taken into account in the unit tests. We are therefore now focusing on the “happy path” and obvious “corner cases”. These could be bugs that have occurred in the past, for example, which are now explicitly included in the tests.
The two approaches to module tests (or integration tests) clearly show that the concept of integration tests is very broad, which is also reflected in various definitions of the International Software Testing Qualifications Board (ISTQB):
-
Integration Testing: Testing performed to expose defects in the interfaces and in theinteractions between integrated components or systems. See also component integration testing, system integration testing.
-
Component Integration Testing: Testing performed to expose defects in the interfaces and interaction between integrated components.
-
System Integration Testing: Testing the integration of systems and packages; testing interfaces to external organizations (e.g. Electronic Data Interchange, Internet).
This often causes confusion and it is not really possible to clearly differentiate between module tests, component tests, integration tests and system integration tests. The transition is actually fluid. Martin Fowler makes a simple distinction between “narrow integration tests” and “broad integration tests”, which differ as follows:
| Narrow Integration Tests | Broad Integration Tests | |
|---|---|---|
| Features |
|
|
| Analogy | Component/Module (Integration) Test | System Integration Test |
Without really realising it, we have just climbed to the next level of the test pyramid.
Pyramiden Level 3: API Smoke Tests & End-to-End Tests

Photo by Bonneval Sebastien on Unsplash
At the transition from the integration tests, we also find the system integration tests with the features just previously described. With these tests, we differentiate between API smoke tests and end-to-end tests. What both have in common is that they test an actual running and complete live version of the software as a black box, only in different ways and with a different focus.
If the system contains graphical user interfaces, these are also included in the tests. This is referred to as end-to-end testing. UI testing frameworks such as Protractor, Selenium or Puppeteer are used to automate web browsers. We slip into the role of a user and click through the application on the interface, make entries, change pages and check whether what is displayed meets our expectations. However, this is not done on the basis of the actual visible graphical user interface but using the markup in the DOM. For example, a UI end-to-end test expects to find a button with a certain label and certain properties in order to then “click” on it and subsequently verify the result of this interaction. Which page do I land on? Do I see the information and data I expect to see?
The focus of the UI end-to-end tests is therefore on inputs, outputs and (user) interactions via the UI components of our software. As these tests are carried out on a live version of the software, the API requests triggered by the UI components are of course also involved. However, they are not the focus here.
The backend system integration tests, on the other hand, are about the API that is (also) used by the UI components and which we test again here in a dedicated manner. We can use Postman or REST-assured again for this, for example. If we run the system integration tests focusing on the APIs in development or test environments, they can also contain requests that change data in order to cover the entire range of possible API requests and interactions.
However, modifying data is a no-go when we run API smoke tests against production systems. Here, it is only a matter of verifying a deployment through read-only access and ensuring that our software system is available in a specific environment and responds to requests in the expected manner. In any case, the real systems of external dependencies are also included here.
End-to-end tests, backend system integration tests and API smoke tests together cover perhaps 10 per cent of the entire system, because specific business logic has already been tested elsewhere, at the lower levels of the test pyramid. We can assume that the individual components work as expected or that we uncover errors and problems elsewhere. Our two types of system integration tests are designed to ensure that the requirements are met, the software system is configured correctly, and works together as expected.
The tests can and should be automated, but not necessarily for every single build. After all, the tests are potentially slower and more time-consuming due to their significantly larger scope. Running them too often may not always be efficient. Ideally, they should therefore be controlled separately via separate build pipelines or jobs. This means that automated test execution can be triggered manually if required. In any case, it is also advisable to trigger them automatically as part of a deployment. The tests at level 3 of our test pyramid are the last level at which we carry out the tests ourselves and automatically. For the last stage, the acceptance tests, we hand over to our customers.
Pyramid Level 4: Acceptance Test

Photo by Alphacolor on Unsplash
Developing software is not an end in itself. The aim is to fulfil the customer’s requirements in order to generate added value for them. We cannot test whether our software achieves this goal on our own. To do this, we need the customer and user of the software to accept it. Acceptance tests are essential for customer satisfaction. The customer decides whether the rocky road on our “stone stairway to heaven” has been worthwhile – the customer is king here too.
Accordingly, the acceptance test in software projects is also one of the last phases before the software goes into productive use. The test begins when all known requirements have been implemented and the most serious errors have been eliminated. The software is then deployed under realistic conditions and tested by technical experts.
Our customers or the end users check the features from the user’s point of view, focusing on the required business functions and the proper functioning of the system, also to check stability. Testing is sometimes even a legal requirement for our customers.
We assume that the software tested under realistic conditions will work just as well in reality.
It is quite possible that errors and problems may still occur during the acceptance test that we did not discover in the other test stages. However, this does not include cosmetic problems, crashes or simple spelling mistakes. It is more about aspects of user-friendliness, in particular intuitive usability and expected behaviour. Is a lot of familiarisation required? Are there perhaps still functions missing that a user would actually expect but which were not previously required? These can often be small things that have simply not been thought of, partly because at some point everyone involved in the project is pretty deep into the subject matter.
In order to clearly document the results of the acceptance tests and be able to repeat them if necessary, they are based on scenarios that already played a role when the requirements were collected in the form of use cases:
Once the customer requirements have been analysed, the test scenarios are compiled, a test plan is defined based on them and test cases are created. The acceptance test can then be carried out and the results recorded.
If the customer requirements are met, our software has successfully passed through the test pyramid and is one step closer to immortality. And if not, we are all one insight richer: we have identified problems and challenges to be solved and can move on to the next iteration.
Graphic by katemangostar on Freepik.com
To be continued …