

Diese oder Teile der Situation kennen sicherlich einige: Unsere Web-Applikation soll mit einem Login geschützt sein. Natürlich wollen wir auch die dahinter liegenden Backend-Services vor unberechtigten Zugriffen von außen absichern und auf andere APIs zugreifen. Das Ganze zudem mit SSO und einem Rechte/Rollen-Konzept.
”Da gab es doch dieses OAuth und auch diese JWT, Access und Refresh Token, Public und Confidential Clients, Authorization Codes, PKCE, Client Secrets und Consent auf Scopes, IDPs und so weiter!“ Klingt wie Buzzword-Bingo? Ist es auch: OAut(sc)h!
Genau hier liegt die Herausforderung, sich der OAuth-Thematik zu nähern. Es gibt unzählige Begriffe und Konzepte, deren Definition und Abgrenzung schwer zu verstehen ist. Das Ziel dieses Blogbeitrages ist es, hier Licht ins Dunkel zu bringen.
Zur Erwärmung starten wir mit einem Thema, welches oftmals für Verwirrung sorgt:
Authentifizierung vs. Autorisierung
Gern werden hier auch die Abkürzungen AuthZ (Authorization) und AuthN (Authentication) verwendet und die Verwirrung ist komplett.
Authentifizierung/AuthN ist der Nachweis einer Identität, beispielsweise durch Eingabe eines Benutzernamens und Passworts. Ein Beispiel aus der Realwelt wäre: Ich gehe mit meinem Personalausweis zum Schalter der Fluglinie am Flughafen. Der Mitarbeiter prüft, ob mein Gesicht mit dem Foto auf dem Ausweis übereinstimmt und weist somit meine Identität nach, um mir meinen Boardpass auszuhändigen.
Autorisierung/AuthZ ist die Zuweisung von Rechten sowie Privilegien auf Ressourcen. Die Identität spielt hier keine Rolle. Ein Beispiel aus der Realwelt wäre: Ich bin im Besitz eines Boardpasses, der mich autorisiert in ein Flugzeug zu steigen. Meine Identität wird beim Einsteigen in das Flugzeug nicht noch mal kontrolliert, sondern nur der Boardpass.
Es bleibt noch zu klären, ob OAuth AuthN oder AuthZ ist. Die Antwort darauf lässt sich im OAuth-Standard The OAuth 2.0 Authorization Framework finden: Es ist Autorisierung!
Toll, und was bringt uns diese Erkenntnis? Kurz gesagt, damit lässt sich der Einsatzzweck von OAuth zu anderen Protokollen, wie OpenID Connect (OIDC), abgrenzen.
Worin unterscheiden sich OAuth und OIDC?
OAuth ist ein Industriestandard-Protokoll, welches den Autorisierungsprozess für den Zugriff von einer Applikation auf andere geschützte APIs mit Hilfe von Access Token spezifiziert. Diese Access Token können wir mit dem Boardingpass am Flughafen vergleichen. Sie autorisieren den Zugriff auf die API.
Schonmal vorab: OAuth Token sollten niemals zur Authentifizierung, beispielsweise zur Anzeige von Nutzerinformationen, verwendet werden. Hintergrund ist, dass dies zu Sicherheitsproblemen in meiner Applikation führen kann, da OAuth keinen Standard für eine sichere Codierung von Nutzerinformationen im Access Token bietet. Sollen Details über den Nutzer im Token gespeichert werden, sollte man sich mit OIDC beschäftigen.
OIDC basiert auf OAuth 2.0 und erweitert dieses um eine Authentifizierungssicht, sodass Nutzerinformationen, wie beispielsweise E-Mail-Adresse oder Vor-und Nachname, angezeigt werden können. OIDC sorgt dabei dafür, dass die Identität eines Nutzers sicher anhand des sogenannten ID-Tokens geprüft wird. Dies erfolgt im Rahmen einer aktuell aktiven User Session.
Zur Unterstützung bei der Auswahl des richtigen Protokolls hier eine kleine Entscheidungshilfe:

OAut(sc)h-Hinweis: Es gibt durchaus Anwendungsfälle, in denen die Nutzer-ID in OAuth Token verwendet wird, damit die gerufene API nutzerspezifische Daten liefern kann. Wird nur diese ID und keine weitere Nutzinformation (Name, E-Mail) verwendet, bewegt man sich noch im OAuth-Standard.
Warum man sich mit OAuth beschäftigen sollte?
Der wesentliche Grund für den Einsatz von OAuth liegt darin begründet, dass es der Industriestandard im Bereich der Autorisierung ist. Speziell im Cloud-Umfeld (Azure, AWS, Google und Co.) ist die Autorisierung von Cloud-Services via OAuth üblich. Durch eine breite Nutzerbasis wird das OAuth-Protokoll stetig verbessert.
Der Vorteil solcher Standardprotokolle wie OAuth ist, dass sie detailliert beschrieben und auf ihre Wirksamkeit getestet sind. Durch den hohen Verbreitungsgrad stehen auch eine Vielzahl von Libraries für alle gängigen Entwicklungs-Frameworks zur Verfügung. Weiterhin existieren fertige und anpassbare Lösungen wie Keycloak oder Auth0, welche uns das Leben leichter machen.
Wir empfehlen an dieser Stelle dringendst, diese fertigen Bestandteile zu verwenden und von einer eigenen Protokoll-Implementierung abzusehen. Bei einer Selbstimplementierung ist das Risiko für ein OAut(sc)h sehr hoch.
Begriffserklärungen zum Auswendiglernen
Der aktuelle Standard ist OAuth 2.0, welcher auf dem IETF Standard The OAuth 2.0 Authorization Framework von 2012 basiert. Im Laufe der Zeit kamen eine Reihe von Erweiterungen, wie beispielsweise zu den Themen “PKCE: Proof Key for Code Exchange” oder “Security Best Current Practices”, hinzu. Eine Übersicht dazu findet sich hier.
Aktuell ist eine Version 2.1 des OAuth-Protokolls in Arbeit, welches als Lessons Learned aus den Erfahrungen von OAuth 2.0 bezeichnet werden kann.
Im weiteren Verlauf werden wir anhand unser Erfahrungen bei pentacor die zwei wichtigsten Flows darstellen. Dabei finden auch Anpassungen aus OAuth 2.1 bereits ihre Anwendung.
Bevor wir auf die verschiedenen Flows eingehen, möchten wir eine Erläuterung der wichtigsten wiederkehrenden Begriffe für Neueinsteiger und Interessierte geben:
Bei einem Resource Server handelt es sich eine geschützte API, auf welche im Rahmen von OAuth der Zugriff autorisiert wird. Er hält die schützenswerten Ressourcen, welche andere Applikationen benötigen.
Unter Scope versteht man die Funktionalität, die der Client auf dem Resource Server nutzen darf. Die Zustimmung zur Verwendung des Scopes nennt man Consent.
Der Resource Owner gewährt den Zugriff auf geschützte Ressourcen über den Resource Server. Dies kann ein Mensch, ein anderer Service oder eine Organisation, wie beispielsweise eine Firma, sein.
Der Client ist die Applikation, welche auf geschützte Informationen des Resource Owners zugreifen möchte. Diese Information liegt auf dem Resource Server. Man unterscheidet bei OAuth hierbei zwischen:
- Public Clients, beispielsweise JavaScript Frontends, welche nicht dazu in der Lage sind, Client Secrets sicher zu verwahren, und
- Confidential Clients, beispielsweise Spring Boot Backends, welche Client Secrets sicher speichern können.
Der Authorization Server ist für die Autorisierung der einzelnen Clients zuständig, indem er ihnen ein Access Token ausstellt. Des Weiteren ist der Authorization Server auch für die Authentifizierung des Resource Owners verantwortlich, beispielsweise beim Authorization Code Flow.
OAut(sc)h: „Waaas? Der Authorization Server ist in OAuth für die Authentifizierung verantwortlich? OAuth ist doch ein Autorisierungs-Framework!”
Richtig gehört. OAuth ist ein Autorisierungs-Framework und wurde zur Authentifizerung und Identifikation eines Nutzers entwickelt. Nichtsdestotrotz ist das Anmelden(Authentifizieren) des Nutzers/Clients notwendig. Wie passt das zusammen?
Ganz einfach: Die Form der Authentifizierung des Resource Owners wird im OAuth-Protokoll nicht spezifiziert. Diese Verantwortung liegt beim Authorization Server. In der Praxis kommt es häufig vor, dass der Authorization Server zur Authentifizierung einen anderen Dienst nutzt. Die Authentifizierung könnte bspw. aber auch durch den Authorization Server mit BasicAuth realisiert werden.
Dann wären da noch die Token, welche in den OAuth Flows zur Autoriserung verwendet werden. Kennen solltet ihr dabei auf jeden Fall das Access Token. Dieses kann man mit dem Boardingpass am Flughafen vergleichen. Dabei werden zwei Arten unterschieden:
Self-Contained Access Token beinhalten alle Informationen, die zur Autorisierung notwendig sind. D.h. der erlaubte Scope oder die ID des Resource Owners sind mögliche Bestandteile des Access Tokens. Um die Integrität dieser Art von Token sicherzustellen, wird eine Signatur verwendet.

Self-Contained Token enthalten alle Autorisierungsinformationen, ähnlich wie der klassische Boardingpass am Flughafen. Photo by Amir Hanna on Unsplash
Opaque Access Token beinhalten lediglich eine ID. Details zur erteilten Autorisierung müssen beim Authorization Server unter Angabe dieser ID erfragt werden. Dies bringt unter anderem den Vorteil mit sich, dass ein Token vor Ablauf seiner Gültigkeit bereits invalidiert werden kann, beispielsweise wenn der Resource Owner seine Zustimmung (Consent) zurückzieht.

Opaque Token beinhalten lediglich eine ID. Photo by Kay Gradert on Unsplash
Prinzipiell stimmt das. JWT sind eine Form von Self-Contained Token. JWT werden vor allem bei OIDC genutzt und dort durch Nutzerinformationen angereichert. Eine Verwendung in OAuth Flows ohne Nutzerinformationen im Token ist aber auch durchaus üblich (siehe RFC 7523 – JSON Web Token (JWT) Profile for OAuth 2.0 Client Authentication and Authorization Grants).
Refresh Token werden genutzt, um neue Access Token beim Authorization Server abzurufen. Sie bieten zwei wesentliche Vorteile, welche vor allem im Authorization Code Flow zum Tragen kommen:
Vorteil 1 – Client-Zugriff ohne aktive Nutzer-Session
Durch die längere Gültigkeit der Refresh Token kann der Client über einen längeren Zeitraum auf den Resource Server zugreifen, ohne dass sich der Resource Owner erneut authentifizieren muss.
Vorteil 2 – Erhöhte Sicherheit durch kurze Access-Token-Gültigkeit
Bei der Verwendung von Refresh Token (längere Gültigkeit) kann die Gültigkeit der Access Token sehr kurz gewählt werden. Das ist von Vorteil, da Access Token, welche in jedem Request mitgesandt werden, für einen Angreifer potenziell leichter abzufangen sind.
Und wie funktioniert OAuth nun?
Es gibt bei OAuth unterschiedliche Flows für verschiedene Anwendungsszenarien. Aktuell üblich sind der Client Credentials und der Authorization Code Flow.
Für die Problemstellung, dass eine Applikation auf eine andere gesicherte API zugreifen soll und die Autorisierung unabhängig vom Benutzer (Resource Owner) ist, bietet sich der Client Credential Flow an.
Soll meine Applikation zusätzlich im Namen eines Nutzers auf eine API und dessen Daten zugreifen, empfiehlt es sich, den Authorization Code Flow zu verwenden. Hierbei erteilt der Resource Owner (Nutzer) explizit seine Zustimmung für den Zugriff auf seine Ressourcen.
Hier eine kleine Entscheidungshilfe:

Bei beiden Flows ist es in der Praxis häufig der Fall, dass die Consumer Applikation und die aufgerufene API von verschiedenen Organisationseinheiten entwickelt werden. Dabei kann die Aushandlung eines Security-Konzepts zwischen Applikation und API sehr aufwendig werden. An dieser Stelle kommt die Stärke des OAuth-Standards zum Tragen. OAuth gibt hier im Rahmen der Flows genau vor, wie sichere Aufrufe zu erfolgen haben und was die jeweiligen Verantwortlichkeiten sind.
Client Credential Flow
Nehmen wir an, wir bauen einen Microservice, welcher uns Informationen zu Produkten liefern soll (ProductService). Dieser Service fungiert als Backend-Komponente von einem Shopsystem.
Freundlicherweise stellen unsere Kollegen uns eine API bereit, die für ein Produkt Bilder liefert (ImageService) und verwenden für die Autorisierung OAuth mit einem Opaque Access Token.
Toll, diese API nutzen wir natürlich gerne.
Für solche Szenarien (Applikation greift auf API zu, ohne Bezug zur Nutzeridentität), bietet sich der Client Credential Flow an.
An dieser Stelle betreten unsere eingangs erwähnten Protagonisten die Bühne:
Der ProductService ist unser Confidential Client und möchte auf Ressourcen vom ImageService zugreifen. Das heißt, der ImageService ist unser Resource Server. Die Zugriffe vom Client auf den Resource Server werden vom Authorization Server autorisiert.
Super, dann können wir starten! Wir müssen nur noch unseren Client beim Authorization Server registrieren (inklusive Angabe der beantragten Scopes) und erhalten im Gegenzug unsere Client ID und unser Client Secret.
Los geht’s!

Will der ProductService nun Bild-Informationen vom ImageService abrufen, kann er dies zunächst nicht, da er kein gültiges Access Token besitzt. Eine Anfrage ohne gültiges Access Token würde hier mit einem HTTP Status 401 (unauthorized) quittiert werden.
Die Schritte im Client Credential Flow sind nun die folgenden:
A) Access Token Request
Unser ProductService (Client) fragt beim Authorization Server ein Access Token an. Hierbei authentifiziert er sich via Client Credentials. Optional kann noch der Scope mitgesendet werden, um gezielt den Zugriff auf notwendige Ressourcen zu beantragen.
B) Access Token Response
Nach erfolgter Verifikation durch den Authorization Server gibt dieser ein Access Token zurück, womit unser Client den Nachweis erhält, dass er als Confidential Client auf die Ressourcen einer anderen Anwendung (Resource Server) zugreifen darf.
C) Image Data Request
Nun fragt unser ProductService Bilder beim ImageService (Resource Server) an. Dabei schickt er das Access Token als Autorisierungsnachweis mit.
D) Token Introspection Request
Da wir ein Opaque Token verwenden, muss der Image Service beim Authorization Server anfragen, ob dass genutzte Access Token gültig und aktiv ist. Dieser Authorization-Server-Endpunkt sollte abgesichert werden. In der Praxis geschieht dies über Firewall-Regeln, Zertifikate, API-Keys oder sogar mit Client Secrets über einen weiteren Client Credential Flow.
E) Token Introspection Response
In Folge der Prüfung des Access Tokens bestätigt der Authorization Server dessen Gültigkeit. Zusätzlich kann in der Response auch der ausgestellte Scope und die verbleibende Gültigkeitsdauer zurückgegeben werden.
F) Image Data Request
Da die Autorisierung unseres ProductServices durch den Authorization Server bestätigt wurde, stellt der ImageService nun die gewünschte Ressource für unseren Client bereit.
Ein typisches Problem, auf welches bei der Implementierung eines OAuth-Prozesses gestoßen wird, ist die hohe Zahl an Aufrufen im System. Es werden für jeden Request neue Token angefragt und validiert, wodurch alle drei dargestellten Komponenten miteinander kommunizieren müssen.
Vorab: Wird bei jedem Request an den Client anschließend der Flow A-F durchlaufen, läuft etwas falsch.
Dies sollte verhindert werden, indem die Restlaufzeit des Access Tokens vom Authorization Server bereitgestellt wird und zusammen mit dem Token vom Client gecacht wird. Solange das Token noch gültig ist, ruft der Client mit diesem den Resource Server auf. Somit werden nach Ausstellung des Access Tokens durch den Authorization Server nur noch die Schritte von C bis F durchlaufen.
Es besteht sogar die Möglichkeit, bis auf C bis F zu reduzieren, indem Self-Contained Token genutzt werden.
Authorization Code Flow
Der Authorization Code Flow ist das Mittel der Wahl, wenn der Zugriff einer Applikation auf einen anderen Service nicht ohne explizite Autorisierung des Nutzers erfolgen darf.
Ein Beispiel-Szenario wäre, dass wir eine Web-Anwendung entwickeln, die es dem Nutzer ermöglicht, Smart-Home-Geräte über die Smart Home API des Herstellers zu steuern. Dazu gehört sowohl der direkte Befehl (“Licht an”) durch den Nutzer als auch die Zeitsteuerung (“Weihnachtsbeleuchtung täglich um 16 Uhr einschalten”) über die Applikation, ohne dass sich der Nutzer für Letzteres jedes mal anmelden muss.
Was bräuchte es dazu?
Zunächst brauchen wir eine API, über die wir unsere Smart-Home-Produkte steuern können. Diese wird uns freundlicherweise vom Smart-Home-Hersteller bereitgestellt und unterstützt die Autorisierung mit Hilfe des OAuth Authorization Code Flows. In OAuth-Sprache übersetzt, ist diese API unser Resource Server. Der Hersteller stellt uns auch noch einen Authorization Server zur Verfügung, wo der Benutzer später den Zugriff unserer Anwendung auf seine Smart-Home-Geräte autorisieren kann.
Die von uns entwickelte Applikation besteht aus einem Backend Client und einem Frontend Client.
Das hier beschriebene Szenario könnte man prinzipiell auch ohne ein Backend umsetzen. Wir haben uns in diesem Beispiel aber dagegen entschieden, da die Verwendung eines Backends einen Sicherheitsvorteil mit sich bringt. Das liegt darin begründet, dass das Client Secret oder auch das Access Token im Frontend nicht sicher abgelegt werden kann. Daher empfiehlt es sich, die Authentifizierung via Client Secrets und die Token in einer sichereren Backend-Applikation zu speichern.
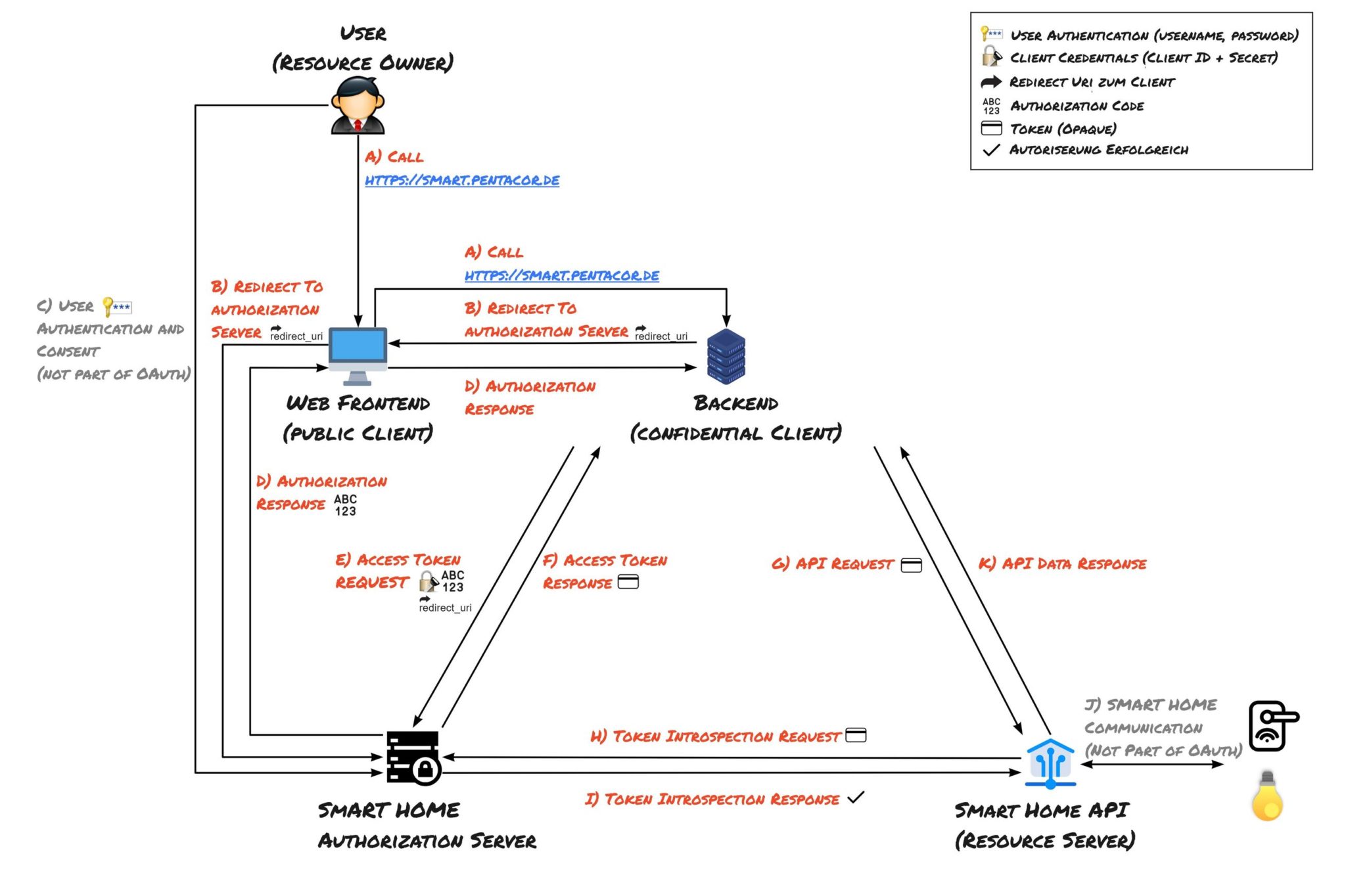
Wie arbeitet der Authorization Code Flow?
A) Call
Der Benutzer (Resource Owner) will unsere neue Applikation ausprobieren. Dazu ruft er die URL der Web-Anwendung auf und authentifiziert sich mit Nutzername und Passwort.
Damit der Nutzer nun beispielsweise das Licht einschalten kann, muss er unserer Applikation erlauben über die Smart Home API (Resource Server) auf seine Lampen zuzugreifen. Dazu wählt er den Hersteller seiner smarten Leuchten aus, authentifiziert sich bei diesem und stimmt einer Weiterleitung zum Authorization Server des Herstellers zu.
B) Redirect to Authorization Server
Mit diesem Redirect zum Authorization Server des Herstellers beginnt der eigentliche Authorization Code Flow. In den Query-Parametern des Redirects werden die ID unserer Applikation (Client ID), die URL unserer Anwendung (redirect_uri) und der notwendige Scope an den Authorization Server gesendet. Ein denkbarer Scope in diesem Beispiel wäre “LampenEinUndAusschalten” und “AlleLampenAuflisten”.
C) User Authentication und Consent
Da es sich hier um den Zugriff auf eine geschützte Ressource handelt, ist auch hier ein Login des Nutzers beim Authorization Server notwendig.
Ihr ahnt es vielleicht schon …
Doch, das ist absolut richtig. Die Verwendung der OAuth Flows schließt die Authentifizierung nicht aus. Ob und wie die Authentifizierung stattfindet, ist im OAuth-Protokoll nicht spezifiziert. Beim Authorization Code Flow findet üblicherweise eine Nutzer-Authentifizierung am Client und Authorization Server statt.
… wäre ja auch blöd, wenn jeder die Lampen unseres Nutzer ein- und ausschalten könnte.
Nach erfolgreicher Authentifizierung am Authorization Server erteilt der Nutzer seine Zustimmung (Consent), dass unsere Anwendung (Client) seine Smart Home Devices über das API-Gateway (Resource Server) steuern darf. Die erlaubten Aktionen, die unsere Applikation über die API ausführen kann (“LampenEinUndAusschalten” und “AlleLampenAuflisten”), werden durch den Scope begrenzt.
D) Authorization Response
Hat der Nutzer seinen Consent erteilt, wird der Browser des Nutzers über die “redirect_uri” wieder zurück zu unserer Anwendung umgeleitet. Ein Query-Parameter des Redirects ist der sogenannte Authorization Code. Dabei handelt es sich um einen Code, der später gegen ein Access Token getauscht werden kann.
Das heißt, gleich sollten wir das Licht einschalten können.
E) Access Token Request
Damit unsere Anwendung (Client) im Namen des Nutzers (Resource Owner) die Aktion “Licht einschalten” über den Resource Server (Smart Home API) aufrufen kann, benötigen wir ein Access Token. Im sogenannten Access Token Request werden der Authorization Code und die redirect_uri an den Authorization Server gesendet. Beide Parameter werden durch den Authorization Server mit den Daten aus den Schritten C und D abgeglichen. Da wir hier einen Confidential Client verwenden, sendet unser Client auch noch seine Client Credentials mit, um sich gegenüber dem Authorization Server zu authentifizieren.
F) Access Token Response
Ab diesem Punkt ist der Ablauf analog zum Client Credentials Flow zu sehen.
Nach erfolgter Verifikation durch den Authorization Server gibt dieser ein Access Token zurück, womit unser Client den Nachweis erhält, dass er als Confidential Client auf die Ressourcen des Users in der Smart Home API (Resource Server) zugreifen darf.
G) API Request
Nun fragt das Backend unserer Anwendung (Confidential Client) bei der Smart Home API (Resource Server) an, die Lichter des Nutzers einzuschalten. Dabei wird das Access Token als Autorisierungsnachweis mitgesendet.
H) Token Introspection Request
Auch hier muss die Smart Home API beim Authorization Server anfragen, ob das genutzte Access Token gültig und aktiv ist. (Wir verwenden in dem Beispiel auch wieder ein Opaque Token)
I) Token Introspection Response
In Folge der Prüfung des Access Tokens bestätigt der Authorization Server dessen Gültigkeit. Neben dieser Information können auch weitere Details bereitgestellt werden. Dazu gehören beispielsweise der Scope oder Identifikationsmerkmale, wie beispielsweise die Kunden-ID beim Smart-Home Anbieter, für den das Access Token ausgestellt wurde.
J) API Response
Nach der Prüfung des Tokens (H-I), ist der Zugriff auf die Smart Home API autorisiert. 💡
Licht an! Nach erfolgter Bestätigung der Autorisierung sowie interner Verarbeitung durch den Resource Server wurde der Zugriff gewährt und unser Nutzer konnte erfolgreich sein Licht über unsere Anwendung einschalten und das alles innerhalb von Sekunden.
(Zum Vergleich: Die Lesezeit bis zu diesem O(ooo)Auth-Moment betrug 12 Minuten.)
Fazit
Halten wir also Folgendes fest:
OAuth ist ein Industrie-Standard-Protokoll, welches den Autorisierungsprozess für den Zugriff von einer Applikation auf andere geschützte APIs spezifiziert. Die in OAuth verwendeten Access Token sollten niemals zur Authentifizierung eines Nutzers verwendet werden. Ist dies notwendig, sollte man sich mit OIDC beschäftigen. Innerhalb der OAuth Flows findet zwar auch eine Form der Authentifizerung statt, diese ist dann aber unabhängig vom OAuth Standard.
Für verschiedene Szenarien stehen unterschiedliche Flows zur Verfügung, wobei wir die beiden geläufigsten in diesem Blogbeitrag dargestellt haben. Für die Problemstellung, dass eine Applikation auf eine andere gesicherte API zugreifen soll und die Autorisierung unabhängig vom Benutzer (Resource Owner) ist, bietet sich der Client Credential Flow an.
Soll meine Applikation im Namen eines Nutzers auf eine API in einem anderen Kontext/einer anderen Organisation zugreifen, empfiehlt es sich, den Authorization Code Flow zu verwenden.
Wir bei pentacor haben in unseren Projekten regelmäßig mit OAuth zu tun. In einigen Projekten noch relativ einfach, indem wir Applikationen entwickeln, die über verschiedene OAuth-Flows mit anderen APIs kommunizieren. Auch deutlich komplexere OAuth-Problemstellungen sind uns nicht fremd. Beispielsweise im Kontext des API Managements, wo wir uns mit Fragen beschäftigen wie: “Wie registriere ich eine neue API zur Laufzeit als Resource Server am Authorization Server?” Und ja, auch das geht.
Jedes Projekt hat dabei seine eigenen Herausforderungen und wir erlebten dabei auch schon den ein oder andere “OAut(sc)h, wie war das jetzt nochmal!?”-Moment.
Die Vielzahl an Möglichkeiten innerhalb der OAuth Standards, die Menge an fertigen Bibliotheken und vor allem die Diskussionen und Lessons Learned mit anderen Pentacornesen brachten uns am Ende aber doch zu unserem eigenen O(ooooo)Auth-Moment 🙂.




