
Wir haben uns in der Vergangenheit schon mit verschiedenen Aspekten des Themas “Testing” beschäftigt. Nun ist es an der Zeit tiefer einzutauchen, es ist Zeit sich die Hände dreckig zu machen. Ran an den Speck Code!
Ich lasse euch daran teilhaben, wie ich Unit-Tests angehe, ohne den Anspruch absoluter Wahrheit oder Perfektion. Was folgt, sind keine Regeln und keine Anleitung. Es ist eine Beschreibung dessen, was für mich gut funktioniert. Spoiler: Das ist nicht (immer) Test-driven Development (TDD) und ich folge auch weder (immer) den “Regeln” oder Empfehlungen von Robert “Uncle Bob” Martin noch dem “One Assertion per Test”-Paradigma. Ich denke, ich folge einem pragmatischen Mittelweg, und die Erfahrung von Rob Martin, die er in “Just 10 minutes without a test” beschreibt, kann ich nachempfinden. Es ist immer ein ungutes Gefühl beispielsweise morgens im Daily Scrum zu sagen: “Das Feature ist fertig. Ich schreibe heute nur noch die Unit-Tests dafür”.
Versteht mich nicht falsch, jede(r) hat sicher einen für sich persönlich gut funktionierenden Weg. Dieser ist eben nur nicht meiner. Und müssen wir immer alle dem gleichen Weg folgen? Ich glaube nicht. Viel wichtiger ist, dass wir uns in einem Punkt einig sind: Tests sind wichtig! Unit-Tests sind besonders wichtig!
Meine Grundannahme bei Unit-Tests ist praktisch Murphy’s Law: Alles, was schiefgehen kann, wird auch irgendwann irgendwie irgendwo unter irgendwelchen Umständen schiefgehen. Wir alle kennen sicher die “This should never happen”-Fälle, die wir in unserem Code vorsehen, zum Beispiel beim Fangen von Exceptions. Und dann treten diese Fälle doch ein und wir wundern uns.
Deshalb ist mein Fazit aus Murphy’s Law für die Unit-Tests: Alles, was sinnvoll getestet werden kann, wird auch getestet. Doch was bedeutet hier sinnvoll? Streben wir 100 Prozent Testabdeckung an? Ich strebe eine hohe Testabdeckung relevanter Code-Teile an und achte auch in Reviews darauf. Ein paar Überlegungen dazu gab es auch schon einmal in einem früheren Artikel.
Genug der Vorrede. Wie gehe ich das denn nun im Detail an?

Beispiel: ein einfacher Taschenrechner
Als Test-Objekt nehmen wir eine einfache Java-Klasse Calculator, die mit der Methode calculate()einfache Grundrechenarten verarbeiten kann. Als Eingabe wird ein String verwendet, der per Regular Expression in die Operanden und den Operator aufgeteilt wird, bevor die eigentliche Berechnung ausgeführt wird:
1package de.pentacor.blog.unittesting;
2
3import java.util.regex.Pattern;
4
5public class Calculator {
6
7 private static final String CALCULATION_REGEX =
8 "^(?<a>\\d+)\\s*(?<operator>[+\\-\\*/])\\s*(?<b>\\d+)$";
9 private static final Pattern CALCULATION_PATTERN = Pattern.compile(CALCULATION_REGEX);
10
11 public Double calculate(String calculation) {
12 var matcher = CALCULATION_PATTERN.matcher(calculation);
13
14 if (matcher.find()) {
15 var operator = matcher.group("operator");
16 var a = Double.valueOf(matcher.group("a"));
17 var b = Double.valueOf(matcher.group("b"));
18
19 return switch (operator) {
20 case "+" -> a + b;
21 case "-" -> a - b;
22 case "*" -> a * b;
23 case "/" -> a / b;
24 };
25 }
26
27 throw new IllegalArgumentException("Invalid calculation: " + calculation);
28 }
29}Das ist kein kompliziertes Beispiel und doch ist hier schon einiges los. Und wo was los ist, kann auch was schiefgehen. Was sollten wir also testen?
- dass die Operanden korrekt aus der Eingabe extrahiert werden
- dass der Operator korrekt aus der Eingabe extrahiert wird
- dass die Grundrechenarten korrekt ausgeführt werden
- dass uns nicht alles um die Ohren fliegt, wenn die Eingabe irgendwie “unerwartet” ist
So, wie das Beispiel momentan geschrieben ist, sind unsere Möglichkeiten, diese verschiedenen Dinge unabhängig zu testen, beschränkt, denn wir haben nur eine einzige Methode, die alles macht. Also müssten die Unit-Tests für diese eine Methode auch alles abdecken. So richtig spaßig klingt das jetzt nicht, zumal ein regulärer Ausdruck involviert ist – und damit wird es doch eigentlich immer interessant. Und stellen wir uns nur mal vor, was erst noch los wäre, wenn wir auch noch externe Abhängigkeiten hätten, die in dieser Methode verwendet werden …
Code überhaupt erst (sinnvoll) testbar machen
Die bereitgestellte, extern genutzte Funktionalität kann beliebig komplex sein. Das spricht für ebenso komplexe Tests. Meh. Ich hätte es doch gern einfach …
Überarbeiten wir also die Calculator-Klasse, um uns das Leben einfacher zu machen und verschiedene Dinge separat testen zu können.
Aufteilung in feingranulare Methoden
Nur weil ich einzelne Teile separat testen können will, möchte ich sie aber nicht gleichzeitig auch separat nutzbar haben. Dazu schränke ich also die Sichtbarkeit der Methoden entsprechend ein:
public– und damit von überall aufrufbar – bleibt nur die Methodecalculate().- Alle anderen Methoden werden
privateund können damit bekanntermaßen nur von der Klasse selbst verwendet werden.
Das Ergebnis dieses Refactorings sieht dann wie folgt aus:
1package de.pentacor.blog.unittesting;
2
3import java.util.regex.Matcher;
4import java.util.regex.Pattern;
5
6public class Calculator {
7
8 private static final String CALCULATION_REGEX =
9 "^(?<a>\\d+)\\s*(?<operator>[+\\-\\*/])\\s*(?<b>\\d+)$";
10 private static final Pattern CALCULATION_PATTERN = Pattern.compile(CALCULATION_REGEX);
11
12 public Double calculate(String calculation) {
13 var operator = extractOperator(calculation);
14 var a = extractOperand(calculation, "a");
15 var b = extractOperand(calculation, "b");
16
17 return switch (operator) {
18 case "+" -> add(a, b);
19 case "-" -> subtract(a, b);
20 case "*" -> multiply(a, b);
21 case "/" -> divide(a, b);
22 default -> throw new IllegalArgumentException("Invalid calculation: " + calculation);
23 };
24 }
25
26 private Double extractOperand(String calculation, String operand) {
27 return Double.valueOf(extractNamedGroupFrom(calculation, operand));
28 }
29
30 private String extractOperator(String calculation) {
31 return extractNamedGroupFrom(calculation, "operator");
32 }
33
34 private String extractNamedGroupFrom(String calculation, String groupName) {
35 Matcher matcher = CALCULATION_PATTERN.matcher(calculation);
36 if (matcher.find()) {
37 return matcher.group(groupName);
38 }
39 return null;
40 }
41
42 private double add(Double a, Double b) {
43 return a + b;
44 }
45
46 private double subtract(Double a, Double b) {
47 return a - b;
48 }
49
50 private double multiply(Double a, Double b) {
51 return a * b;
52 }
53
54 private double divide(Double a, Double b) {
55 return a / b;
56 }
57}<code data-language="java"></code>Die öffentliche Methode ist in erster Linie diejenige, die die wesentliche Funktionalität meiner Klasse bereitstellt. Dass diese getestet werden (muss), versteht sich von selbst. Da sie öffentlich sichtbar ist und von überall verwendet werden kann, ist das auch kein Problem. Die Herausforderung steckt jetzt allerdings im Detail, im wahrsten Sinne des Wortes.
Die privaten Methoden kapseln die Einzelteile der Funktionalität in kleine, einfach zu verstehende Units. Und was einfach zu verstehen ist, ist auch einfach zu testen. Das soll uns jedoch nur intern helfen und nicht von außen verwendet werden, schließlich wollen wir unsere Abhängigkeiten unter Kontrolle halten. Entsprechend sind die Methoden nicht nur gekapselt, sondern auch verborgen.
Problem gelöst! Ja, jetzt kommt wirklich keiner mehr ran. Auch nicht unser Test, der schließlich in einer separaten Klasse im Verzeichnis src/test/java im gleichen Package implementiert ist. Doof.
Für einen Test der öffentlich sichtbaren Methode calculate() ist das jedoch zunächst kein Problem. Ein beispielhafter Unit-Test könnte so aussehen:
1@Test
2void calculate_withAddition_returnsExpectedResult() {
3 // arrange
4 Calculator calculator = new Calculator();
5 String input = "2 + 3";
6 Double expectedResult = 5d;
7
8 // act
9 Double result = calculator.calculate(input);
10
11 // assert
12 assertNotNull(result);
13 assertEquals(expectedResult, result);
14}Methoden für den Test zugänglich machen
Für eine private Methode sieht das Bild allerdings gleich ganz anders aus. Da müssen wir erst einmal eine Möglichkeit bekommen, auf die Methode zuzugreifen.
Reflections to the rescue! Java bietet ja die Möglichkeit, über Reflections auf Klassen und Methoden zuzugreifen, die Sichtbarkeit zu verändern und sie dann auszuführen und so in unseren Unit-Tests zugänglich zu machen … Problem wieder gelöst!
1@Test
2void add_withValidOperands_returnsExpectedResult()
3 throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
4 // arrange
5 Double a = 2d;
6 Double b = 3d;
7 Double expectedResult = 5d;
8
9 Method add = Calculator.class.getDeclaredMethod("add", Double.class, Double.class);
10 add.setAccessible(true);
11
12 // act
13 Double result = (Double) add.invoke(calculator, a, b);
14
15 // assert
16 assertNotNull(result);
17 assertEquals(expectedResult, result);
18}Bevor wir die Methode add() testen können, müssen wir uns erst einmal Zugang verschaffen und die Methode ausführbar machen, bevor wir sie ebenfalls über Reflections ausführen, auf der vorher bereits verwendeten Instanz calculator. Leider sind die Reflections nicht generisch, sodass wir das Ergebnis erst noch auf den gewünschten Typ casten müssen. Allein durch die Verwendung von Reflections könnte dieser ziemlich simple Test (theoretisch) also schon mal drei verschiedene Exceptions werfen, die deklariert werden müssen, ganz zu schweigen von möglichen Runtime Exceptions, wie beispielsweise einer Exception beim Cast von Object auf Double.
Natürlich, das sind vergleichsweise künstliche Überlegungen, die nicht eintreten sollten. “This should never happen.” Moment, da war doch was … Murphy’s Law. Was schiefgehen kann, wird auch schiefgehen. Ich würde mich besser fühlen, wenn ich die Komplexität der Reflections aus meinen Tests verbannen kann.
Meine Lösung: Ich nutze die Standard-Sichtbarkeit der Methoden, entferne also den Modifier private. Damit sind sie aus dem gleichen Package wie dem der implementierenden Klasse erreichbar und unser beispielhafter Test kann deutlich vereinfacht werden:
1@Test
2void add_withValidOperands_returnsExpectedResult() {
3 // arrange
4 Double a = 2d;
5 Double b = 3d;
6 Double expectedResult = 5d;
7
8 // act
9 Double result = calculator.add(a, b);
10
11 // assert
12 assertNotNull(result);
13 assertEquals(expectedResult, result);
14}<code></code>Sollten jetzt noch Exceptions geworfen werden, kommen sie aus der Methode, die ich testen möchte, also aus der Business-Logik statt aus der Test-Implementierung.
Anatomie eines Unit-Tests
In den Beispielen der Testfälle sind einige der Konventionen zu sehen, die ich beim Schreiben meiner Unit-Tests befolge:
Name der Test-Methode
Die Namen meiner Testfälle, also Test-Methoden, haben drei separate Teile, die jeweils mit _ separiert sind:
- der Name der getesteten Methode:
add - die Testbedingung, also eine knappe Beschreibung des Testfalls:
withValidOperands - das erwartete Ergebnis:
returnsExpectedResult
Daraus ergibt sich eine einigermaßen gut lesbare und sprechende Beschreibung des Testfalls. Je nach Methode, Bedingung und erwartetem Ergebnis kann das allerdings zu (für Java nicht untypischen) extrem langen Methodennamen führen, doch dazu später mehr.
Arrange-Act-Assert-Pattern
Ich bin ein Freund des Arrange-Act-Assert-Patterns, das es ermöglicht, Testfälle durch einfache Kommentare klar zu strukturieren und in Abschnitte zu unterteilen:
Arrange – Vorbereitung des Tests
Eingabewerte werden vorbereitet und erwartete Ergebnisse definiert. Bei externen Abhängigkeiten, die gemockt werden, nutze ich diesen Bereich auch, um das Verhalten der Mocks zu definieren. Müssen Testdaten in die Datenbank eingefügt werden? Hier findet es statt (doch da sprechen wir eigentlich schon über einen Integrationstest).
Act – der Test
Der eigentliche Test findet statt. Die zu testende Methode wird ausgeführt bzw. der für den Test relevante REST-Call gemacht. Sonst passiert hier nichts. In jedem Fall fällt aus dem Abschnitt Act aber irgendein Ergebnis heraus.
Assert – Auswertung des Tests
Die Assertions werden auf das Ergebnis angewendet. Das sollten nicht zu viele sein, mindestens aber eine. In manchen Fällen, beispielsweise bei komplexeren Ergebnissen mit Elementen in Listen oder Maps, kann es auch sinnvoll sein, einzelne Elemente herauszunehmen und weitere Assertions darauf anzuwenden.
Naturgemäß sind die Abschnitte Arrange und Assert länger als Act. In vielen Fällen ist Arrange der vermutlich längste, gerade wenn viel Vorbereitung erforderlich ist, weil die Eingaben oder erwarteten Ergebnisse sehr komplex sind, viel gemockt werden muss usw. In diesen Fällen bietet sich die Frage an, ob beim Test-Code das gleiche Vorgehen wie beim produktiven Code angewendet werden kann und sollte: Lassen sich Teile in eigene (Hilfs-) Methoden auslagern?
Habe ich dagegen sehr viele Assertions in meinem Testfall, sollte ich mich eher fragen, ob ich vielleicht versuche zu viele Dinge auf einmal zu testen. Wäre es unter Umständen besser, meinen Testfall in mehrere kleinere Testfälle aufzuteilen, die jeweils die Assertions für einen Teil-Aspekt enthalten? Wovon ich in diesem Zusammenhang kein Freund bin: Hilfsfunktionen für Assertions à la checkResult() zu schreiben, die dann wiederum alle Assertions enthalten und potenziell in verschiedenen Tests immer wieder verwendet werden.
Unit-Tests haben normalerweise den großen Vorteil, dass sie Methoden durch beispielhafte Ausführung “dokumentieren” – das wird durch Auslagerung von Assertions in (intransparente) separate Methoden erheblich erschwert. Das gleiche gilt übrigens, wenn die unter Arrange verwendeten Eingaben zu größten Teilen aus woanders definierten Variablen und Konstanten herangezogen werden.
Das richtige Maß zu finden, ist also in vielen Fällen eine Gratwanderung. Persönlich nehme ich allerdings eher Redundanz in Kauf und habe dafür einen Test, bei dem ich Eingabe und Ausgabe auf einen Blick erkennen kann, ohne dass ich dafür noch in sechs weitere Dateien schauen und zu drei anderen Methoden scrollen muss.
Wo wir gerade beim Thema Übersichtlichkeit und Erfassen von Tests auf einen Blick sind: In manchen Fällen fasse ich die Abschnitte Act und Assert auch zusammen, also insbesondere dann, wenn die Assertion es erfordert, dass der Aufruf der getesteten Funktion innerhalb der Assertion erfolgt:
1@Test
2void calculate_withInvalidInput_throwsException() {
3 // arrange
4 Calculator calculator = new Calculator();
5 String input = "foo bar";
6
7 // act & assert
8 assertThrows(IllegalArgumentException.class, () -> calculator.calculate(input));
9}<code data-language="java"></code>Würde ich krampfhaft an der vorherigen dreiteiligen Struktur festhalten wollen, müsste ich den Testfall so schreiben:
1@Test
2void calculate_withInvalidInput_throwsException() {
3 // arrange
4 Calculator calculator = new Calculator();
5 String input = "foo bar";
6
7 // act
8 Executable methodCall = () -> calculator.calculate(input);
9
10 // assert
11 assertThrows(IllegalArgumentException.class, methodCall);
12}Das ist zwar möglich, doch aus meiner Sicht sinnlos. Eine mögliche Ausnahme: Der zu testende Methoden-Aufruf hat sehr viele Argumente, ist irgendwie unübersichtlich oder aus anderen Gründen komplex. Selbst in diesem Fall liegen Problem und Lösung allerdings sehr wahrscheinlich woanders.
Was ich in den meisten Fällen auch nicht mache: Tests auf eine Zeile reduzieren. So gern ich meinen produktiven Code knapp halte und nach Möglichkeit auf wenige Zeilen reduziere, so gern halte ich der Konsistenz und Lesbarkeit wegen am Arrange-Act-Assert-Pattern fest. Doch urteilt selbst, ob euch dieser Test besser gefällt als die vorherigen Beispiele:
1@Test
2void calculate_withAddition_returnsResult() {
3 assertEquals(5, calculator.calculate("2 + 3"));
4}<code data-language="java"></code>Test-Klassen-Organisation
Je nachdem, wie viel Funktionalität und Komplexität in einer Klasse steckt und wie viele verschiedene Testfälle es abzudecken gilt, kann eine Test-Klasse schnell ziemlich lang und unübersichtlich werden.
Da könnte man jetzt beispielsweise anfangen, mehre Test-Klassen für eine einzelne “Produktiv-Klasse” zu schreiben. Der Gedanke überzeugt mich jedoch nicht. CalculatorTest als Test für Calculator ist logisch und naheliegend. Was mache ich aber, wenn ich einzelne Klassen für die Tests einzelner Methoden schreiben will? Ende ich dann mit einem solchen Konstrukt?
AbstractCalculatorTestals abstrakte Parent-Klasse für alle einzelnen Klassen für die gemeinsame Initialisierung und Vorbereitung der Tests insgesamtCalculateCalculatorTestfür Tests der Funktioncalculate()AddCalculatorTestfür Tests der Funktionadd()- …
Oder müsste ich die einzelnen Klassen nicht eher so benennen, dass Calculator vorn steht und alphabetisch sortiert die Tests einzelner Methoden einer Klasse zusammen?
CalculatorAbstractTestCalculatorAddTestCalculatorCalculateTest- …
Naming – eines der schwierigsten Probleme. Man kennt es.
Nein, was ich stattdessen mache, ist ein IDE-Feature zu nutzen: IntellIJ IDEA erlaubt es, mittels Kommentaren im Code Regionen zu definieren, die dann zusammengeklappt werden können. Damit würde eine Test-Klasse insgesamt etwa so aussehen:
1package de.pentacor.blog.unittesting;
2
3import static org.junit.jupiter.api.Assertions.*;
4
5import java.lang.reflect.InvocationTargetException;
6import java.lang.reflect.Method;
7import org.junit.jupiter.api.Test;
8import org.junit.jupiter.api.function.Executable;
9
10class CalculatorTest {
11
12 Calculator calculator = new Calculator();
13
14 // region calculate()
15
16 @Test
17 void calculate_withAddition_returnsResult() {
18 // arrange
19 String input = "2 + 3";
20 Double expectedResult = 5d;
21
22 // act
23 Double result = calculator.calculate(input);
24
25 // assert
26 assertNotNull(result);
27 assertEquals(expectedResult, result);
28 }
29
30 @Test
31 void calculate_withInvalidInput_throwsException() {
32 // arrange
33 String input = "foo bar";
34
35 // act
36 Executable methodCall = () -> calculator.calculate(input);
37
38 // assert
39 assertThrows(IllegalArgumentException.class, methodCall);
40 }
41
42 // endregion
43
44 // region add()
45
46 @Test
47 void add_withValidOperands_returnsResult() {
48 // arrange
49 Double a = 2d;
50 Double b = 3d;
51 Double expectedResult = 5d;
52
53 // act
54 Double result = calculator.add(a, b);
55
56 // assert
57 assertNotNull(result);
58 assertEquals(expectedResult, result);
59 }
60
61 // endregion
62}<code data-language="java"></code>Die Regionen oder Abschnitte können auch beliebig ineinander verschachtelt werden, so dass sie eine gute Möglichkeit bieten, lange Source Files zu strukturieren und zu organisieren. Das funktioniert übrigens auch in beliebigen anderen Dateiformaten, wie beispielsweise YAML oder SQL, und ist damit eine unbedingte Empfehlung.
Auswahl von Testfällen
Wir haben jetzt gesehen, wie ich meine Tests grundsätzlich schreibe und ich hatte anfangs auch angedeutet, alle denkbaren Fälle abdecken zu wollen. Das bedeutet insbesondere:
- Eingabewert
nullfür alle Argumente einer Methode - leere Eingabewerte für alle Argumente einer Methode, also insbesondere
"",Collections.emptyList()usw. - ungültige Eingabewerte
- gültige Eingabewerte für den Happy Path (natürlich)
Auf den ersten Blick scheint das, auch schon mit Blick auf das Beispiel der Klasse Calculator, nicht notwendig zu sein, denn der als Eingabe verwendete String muss ja am regulären Ausdruck für die Rechnung vorbei. Und eben dieser Ausdruck ^(?<a>\d+)\s*(?<operator>[+\-\*/])\s*(?<b>\d+)$ sieht vor:
- Der String beginnt mit einer Zahl bestehend aus mindestens einer Ziffer.
- Auf den ersten Operanden
afolgt eine beliebige Zahl an Leerzeichen. - Es folgt der Operator, der entweder
+,-,*oder/ist. - Auf den Operator folgt wieder eine beliebige Zahl an Leerzeichen.
- Der String endet schließlich mit einer Zahl bestehend aus mindestens einer Ziffer.
Was sollte also schiefgehen?
In der allerersten Version des Rechners konnte zugegebenermaßen tatsächlich noch gar nicht so viel passieren. Einige Probleme haben wir erst durch das Aufteilen der Funktionalität in separate Funktionen eingeführt (ironischerweise): Dadurch, dass die Extraktion des Operators aus dem String und seine anschließende Auswertung jetzt in unterschiedlichen Kontexten stattfinden – also insbesondere das switch-Statement unabhängig von einem Match der Eingabe auf den regulären Ausdruck ausgeführt wird –, haben wir uns plötzlich das sehr reale Risiko einer NullpointerException in den Code geholt. Diese fällt auf, wenn wir die Methode calculate() mit einer ungültigen Eingabe aufrufen.
Zur Lösung des Problems gibt es verschiedene Möglichkeiten, die wiederum an verschiedenen Stellen getestet werden können. Beispielsweise könnte die neue Methode extractOperator() direkt eine Exception werfen, wenn kein gültiger Operator aus der Eingabe extrahiert werden kann. Oder die Funktion calculate() wird um einen zusätzlichen Null-Check erweitert. Darum soll es jetzt jedoch gar nicht im Detail gehen.
Viel wichtiger ist es, im Hinterkopf zu behalten, dass Methoden immer auch mit eigentlich (aktuell) “nicht möglichen” Bedingungen getestet werden sollten, um spätere Überraschungen zu vermeiden. Wie wir gesehen haben, können die schon durch einfache Refactorings schnell und leicht entstehen.
Und denken wir noch ein Stück weiter: Wir haben auch die Methoden für die Ausführung der eigentlichen Berechnungen als private Methoden extrahiert. An der Stelle könnte man durchaus darüber diskutieren, ob die nicht auch public sein könnten oder sollten, schließlich ergibt das für einen Rechner durchaus Sinn. Es gibt nicht unbedingt einen nachvollziehbaren Grund sie zu verstecken, außer: Die vormals allein intern verwendeten Methoden könnten nun von gänzlich anderen, potenziell unbekannten Stellen verwendet werden, auf unklare Weise, mit möglicherweise ungültigen Eingabewerten. Diese ungültigen und unerwarteten Eingaben führen dann zu unerwarteten Fehlern, wenn wir uns nicht vorher bei der Auswahl unserer Test Cases schon auf alle Eventualitäten vorbereitet haben.
Haben wir das am Anfang versäumt, wird es später deutlich schwieriger. Daher ist es auch unerlässlich, beim Auftreten von Bugs unbedingt erst einmal einen Test zu schreiben, der den Bug reproduziert, bevor er gefixt wird. Das erhöht auf Dauer definitiv die Sicherheit und Robustheit der Anwendung, auch im Blick auf künftige Refactorings.
Parametrisierte Tests
Häufig ist es so, dass viele Tests sich eigentlich nur in ihren Eingaben unterscheiden, aber das gleiche Ergebnis erwarten oder die Ausführung des Tests im Prinzip identisch ist und der Tests sozusagen eine Funktion f (Eingabe, Ausgabe) ist. In diesen Fällen macht uns JUnit 5 mit der Test-Annotation @ParameterizedTest das Leben um ein Vielfaches leichter, denn wir brauchen den grundsätzlichen Test nur einmal zu definieren und können ihn dann beliebig oft mit verschiedensten Parametern ausführen.
Welche Parameter verwendet werden, hängt dabei von weiteren Annotations ab. Am einfachsten ist @NullSource – damit wird dem Test einfach nur null als Parameter übergeben. Zugegeben, das ist für sich allein genommen nicht supersinnvoll, in Kombination mit @ValueSource dagegen schon sehr viel mehr. Schauen wir uns ein Beispiel an:
1@ParameterizedTest
2@NullSource
3@ValueSource(doubles = {0d, 1d, 2d, 3d, 4d})
4void add_withParameters_returnsExpectedResult(Double a) {
5 // arrange
6 Double b = 1d;
7 Double expectedResult = a != null ? a + b : b;
8
9 // act
10 Double result = calculator.add(a, b);
11
12 // assert
13 assertEquals(expectedResult, result);
14}<code data-language="java"></code>Damit dieser Test auch tatsächlich erfolgreich ist, habe ich “heimlich” die Methode so angepasst, dassnullals Eingabe wie0dbehandelt wird. 🤓
Aus meiner Sicht eignet sich diese Art der parametrisierten Tests vor allem für das Testen von Fehlerfällen, in denen verschiedenste ungültige Eingaben alle zum gleichen Ergebnis, nämlich zu einer erwartungsgemäßen Fehlerbehandlung, führen sollen.
Deutlich flexibler und von mir lieber verwendet ist die Annotation @MethodSource. Damit wird eine Methode angegeben, die die Argumente für den parametrisierten Test bereitstellt. Anders als bei @ValueSource können das beliebig viele Argumente beliebiger Typen sein, so dass ein Test der Methode add() so aussehen könnte:
1@ParameterizedTest
2@MethodSource("add_params")
3void add_withParameters_returnsExpectedResult(Double a, Double b, Double expectedResult) {
4 // act
5 Double result = calculator.add(a, b);
6
7 // assert
8 assertEquals(expectedResult, result);
9}
10
11static Stream<Arguments> add_params() {
12 return Stream.of(
13 Arguments.of(null, null, 0d),
14 Arguments.of(1d, null, 1d),
15 Arguments.of(null, 1d, 1d),
16 Arguments.of(2d, 3d, 5d),
17 Arguments.of(23d, 6d, 29d),
18 Arguments.of(1200d, 34d, 1234d)
19 );
20}Finetuning der Ausgabe
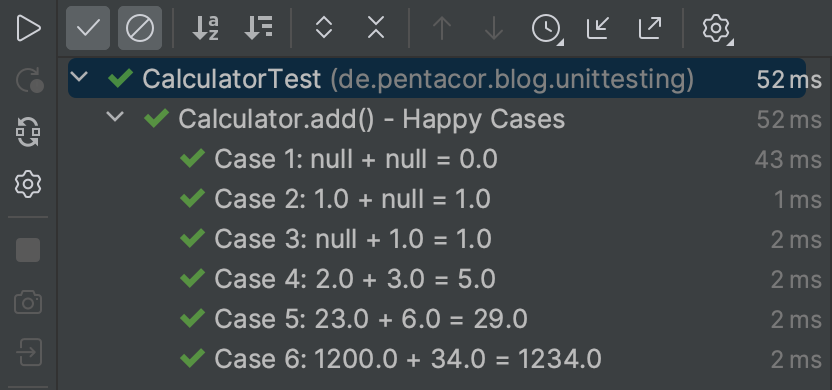
Ich hatte die Konvention bei der Benennung von Test-Methoden beschrieben und auch erwähnt, dass die Namen nicht in jedem Fall wirklich gut lesbar sind. Mit JUnit 5 gibt es auch dafür eine Lösung, die insbesondere in Verbindung mit parametrisierten Tests richtig glänzt: Wir können mit der Annotation @DisplayName beliebige Namen für Test-Klassen und -Methoden vergeben. Mittels des Attributs name ist das auch für die einzelnen parametrisierten Testausführungen möglich, wobei auch Parameter-Werte in der Bezeichnung verwendet werden können, beispielsweise:
1@DisplayName("Calculator.add() - Happy Cases")
2@ParameterizedTest(name = "Case {index}: {0} + {1} = {2}")
3@MethodSource("add_params")
4void add_withParameters_returnsExpectedResult(Double a, Double b, Double expectedResult) {
5 // act
6 Double result = calculator.add(a, b);
7
8 // assert
9 assertEquals(expectedResult, result);
10}<code data-language="java"></code>Das Ergebnis der Test-Ausführung ist dann wunderbar lesbar und “menschenfreundlich”:
Zusammenfassung
Mit diesem Artikel habe ich einen Einblick in meine persönliche Sicht auf die Grundlagen des Unit-Testings gegeben. Wir haben gesehen, wie man den Code so strukturiert, dass er feingranular getestet werden kann. Meine Vorlieben für die Gestaltung oder Organisation von Test-Klassen habt ihr auch kennen gelernt und ich habe einige wesentliche Fälle genannt, die meiner Ansicht nach in keinem Unit-Test fehlen sollten – und warum bzw. welche Fallstricke dazu führen können, dass gerade die “unmöglichen” Fälle ziemlich wichtig werden. Damit das Testen auch wirklich Spaß macht und schön anzusehen ist, habt ihr auch meine Lieblings-Annotationen aus JUnit 5 kennen gelernt.
Da fehlt eigentlich nur noch eins: die benötigten Dependencies. Für die Beispiele aus diesem Artikel werden die Bibliotheken junit-jupiter-engine und junit-jupiter-params benötigt. Dann kann es auch schon losgehen!
Happy Testing! Und nicht vergessen: Was schiefgehen kann, wird schiefgehen – was getestet werden kann, sollte getestet werden!




