
Wo drückt der Schuh?

In den letzten Jahren habe ich einige Software-Projekte gesehen, die man „landläufig“ als CRUD-Anwendungen bezeichnet. Diese Anwendungen sind sehr datenzentriert und bieten viele tabellarische Ansichten in der UI.
Die Projekte hatten meist eine klassische 3-Layer-Architektur, doch waren sie darüber hinaus wenig modularisiert. Was zu Beginn ein hinreichender Ansatz war, hat sich über die Zeit zu einem unstrukturierten Monolithen entwickelt, aka der „Big Ball of Mud“.
Die folgende Abbildung zeigt die Abhängigkeiten einer solchen Applikation.
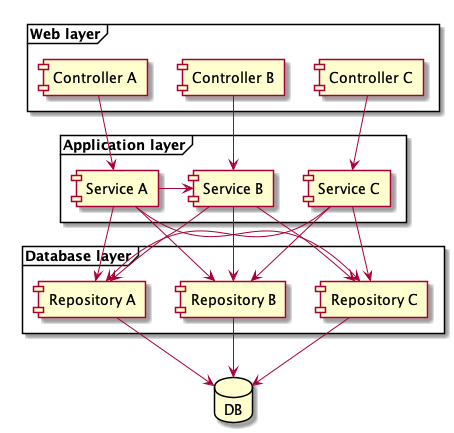
Wie zu erkennen ist, teilen sich die Services mehrere Repositories. Das führt zu einer engen Kopplung und macht es immer schwieriger, das System anzupassen. Mit jeder Änderung steigt der gefühlte Schmerz der Entwickler.
Es scheint also eine Herausforderung zu sein, die große Anzahl an verschiedenen Abfragen für die tabellarischen Ansichten sauber zu modularisieren. Das lässt die Repositories immer weiter wachsen.
Die tabellarischen Ansichten benötigen oft Aggregationen über mehrere Entitätstypen. Dabei fehlt es meist an klaren Regeln, wo speziell dieser Code hingehört.
Schlussendlich nutzt dann ein Application Service A sowohl Repository A als auch Repository B, um seine Aggregation umzusetzen. Application Service B seinerseits nutzt ebenfalls Repository A und B für seine Aggregationen …
Eine Alternative zu diesen wachsenden Repositorys bietet das Command-Query-Separation Pattern.
Was ist das Command-Query-Separation-Pattern?
In seinem Buch Object-Oriented Software Construction formulierte Bertrand Meyer bereits 1988 die Idee, schreibende und lesende Operationen zu trennen.
Das Pattern ist seither als Command-Query-Separation (CQS) bekannt und somit ein „alter Hut“ der Softwareentwicklung. Dennoch scheint es mir, dass es oft übersehen wird und seine positiven Auswirkungen auf den Code unterschätzt werden.
Eine Art das Pattern zu implementieren zeigen die folgenden Java-Listings. Dabei wird nur der Query-Teil des Patterns gezeigt. Den Command-Teil kann man äquivalent dazu implementieren.
1interface Query {
2}
3
4interface Response {
5}
6
7interface QueryHandler<Q extends Query, R extends Response> {
8 boolean canExecute(Query query);
9 R execute(Q query);
10}Die Query-Klasse repräsentiert den Typ der Abfrage und die Werte, nach denen gefiltert wird. Der Query-Handler implementiert die eigentliche Abfrage und die Response-Klasse beinhaltet das Ergebnis.
Es folgt ein gekürztes Beispiel. Darin wird der Name eines Nutzers anhand seiner E-Mail-Adresse ermittelt.
1@RequiredArgsConstructor
2@Getter
3class UserNameByEmailQuery implements Query {
4 private final Email email;
5}
6
7@RequiredArgsConstructor
8@Getter
9class UserNameResponse implements Response {
10 private final String userName;
11 private final String fullName;
12}
13
14@RequiredArgsConstructor
15class UserNameByEmailQueryHandler
16 implements QueryHandler<UserNameByEmailQuery, UserNameResponse> {
17
18 private final NamedParameterJdbcTemplate namedParameterJdbcTemplate;
19
20 @Override
21 public boolean canExecute(Query query) {
22 return query instanceof UserNameByEmailQuery;
23 }
24
25 @Override
26 public UserNameResponse execute(UserNameByEmailQuery query) {
27 var sqlEmailParameter = new MapSqlParameterSource()
28 .addValue("queryEmail", query.getEmail().toString());
29
30 return namedParameterJdbcTemplate.queryForObject(
31 "SELECT user_name, full_name FROM users WHERE email = :queryEmail"
32 , sqlEmailParameter
33 , (resultSet, rowNum) -> new UserNameResponse(
34 resultSet.getString("user_name"),
35 resultSet.getString("full_name")));
36 }
37
38}Folgendes Listing zeigt einen Query-Executor-Service, der alle Query-Handler kennt und abhängig vom Query-Typ den entsprechenden Handler aufruft.
1class QueryExecutorService {
2
3 List<QueryHandler> queryHandlers = getAllQueryHandler();
4
5 Response executeQuery(Query query) {
6 return queryHandlers.stream()
7 .filter(queryHandler -> queryHandler.canExecute(query))
8 .map(queryHandler -> queryHandler.execute(query))
9 .findAny()
10 .orElseThrow(() -> new RuntimeException("No QueryHandler found."));
11 }
12
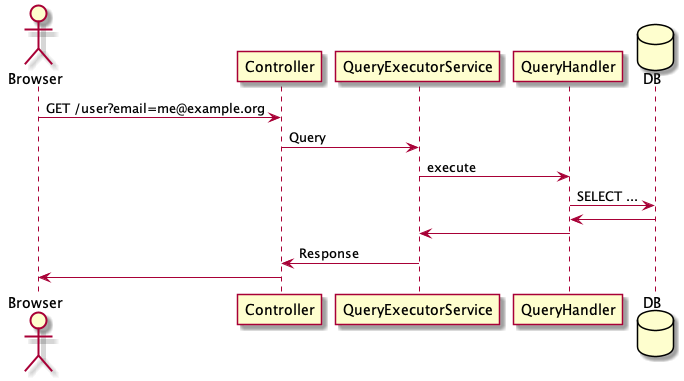
13}Das folgende Sequence-Diagramm zeigt, wie eine Query-Anfrage ausgeführt wird.
Wie kann das Command-Query-Separation-Pattern helfen?
Die konsequente Trennung in statusverändernde Commands und rein lesende Queries bringt viele Vorteile mit sich.
Die lesenden Abfragen können zumeist ausgeführt werden, ohne Geschäftsregeln beachten zu müssen, da keine Statusänderung erfolgt. Man kann also Anpassungen an den Queries getrennt von den Anpassungen der Geschäftsregeln betrachten. Das wirkt sich positiv auf die Modularisierung aus und reduziert die kognitive Belastung der Entwickler.
Außerdem ist klar definiert, wo Code hingehört, auch wenn er mehrere Entitätstypen aggregiert.
Durch das Pattern wird es auch einfacher, allen Query-Handlern eine Read-only-Datenbank-Connection zu geben, die von einem Read-Replica bedient werden kann. Das hilft, die Anwendung zu skalieren, falls es notwendig wird.
Wie setzt man das Command-Query-Separation-Pattern schrittweise um?
Bezogen auf die beschriebenen CRUD-Anwendungen kann man beginnen, die vielen verschiedenen Abfragen als Query-Handler herauszulösen. Übrig bleiben oft Repositories mit den Methoden findById, save und delete. Diese „einfachen“ Repositories lassen sich eineindeutig den Application Services zuordnen. Das verringert die ursprünglich problematische Kopplung, da nun ein Application Service A nur noch ein Repository A benötigt.
Die folgende Abbildung zeigt die Struktur nach der Extraktion der Queries.
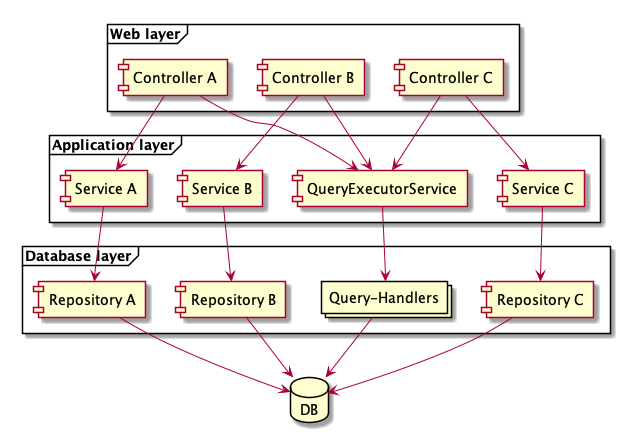
Durch weiteres Refactoring könnte man den restlichen Code der Application Services noch als Command-Handler extrahieren. Ob sich der Aufwand lohnt, muss jedes Projekt für sich entscheiden. In den beschriebenen CRUD-Anwendungen war die gewonnene Modularisierung nach der Extraction der Query-Handler oft gut genug, um den Entwicklern ihre Schmerzen zu nehmen.
Abschließend möchte ich noch darauf hinweisen, dass man auch mit klaren Regeln zur Strukturierung der Repositorys, auch ohne CQS, die Kopplung hätte senken können. Jedoch zeigt meine Erfahrung, dass es in der Praxis selten dazu kommt.
Mit CQS ist diese Strukturierung inhärent im Pattern und es fällt deutlich leichter, das Anwachsen der Repositorys zu vermeiden.
Fazit
Das Command-Query-Separation-Pattern kann eine gute Hilfestellung bieten. Durch die vorgegebene Struktur und klare Trennung der Verantwortlichkeiten verbessert sich die Modularisierung.
Das Pattern lässt sich auch gut mit anderen Ansätzen verbinden, wie zum Beispiel dem Domain-Driven-Design. Auch kann es erweitert werden zum Command-Query-Responsibility-Segregation-Pattern.




